 Forum
Forum OPRR
OPRR Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Data
Data

Systematic interpretation of ZK-Rollup, Optimism-Rollup and Plasma
 Summarized by AI
Summarized by AI
Original title: "Summary and Interpretation of Standardized Ethereum"
Original author: Preethi Kasireddy
Original compilation: Block unicorn
"Blockchain doesn't scale" You've probably heard it a million times. A few years ago, this felt like a real threat to the industry. How do we bank the unbanked if we can't even process 15 transactions per second?
But big problems drive innovation, and blockchain scalability is a big one. It quickly caught the attention of engineers and scientists, and today we are increasingly confident that blockchains can scale. In fact, most of the current debate focuses on which scalability solution will win. That's why in this post, I'm going to break down some of the Ethereum scalability solutions that have been explored over the past five years -- and explain how these are stepping stones to possible winners: Summary
Facing the "scalability trilemma"
If you don't mention the famous "scalability trilemma" ”, we cannot talk about scalability. The term was coined by Vitalik to explain the three properties blockchains are designed to possess: scalability, decentralization, and security. Clearly, we can implement two of these properties so far. But getting all three at the same time is very, very difficult.
Before we understand why, let's make our terms clear.
1. Scalability simply means that the blockchain can handle a large number of transactions, measured in transactions per second (TPS).
2. Decentralization means that the blockchain is run by many "trustless" nodes around the world - rather than by "trusted" nodes in a small cluster. Ren" node runs. 3. Security means that even if a certain percentage of nodes in the network are malicious, the blockchain can resist attacks. Ideally, it should be able to handle up to 50% of malicious nodes. Vitalik created a simple triangle with each side representing one of three properties. Each side of the triangle represents a different type of blockchain solution capable of achieving 2 of the 3 properties.

Decentralization and Security

The bottom of the triangle is a traditional blockchain such as Bitcoin and Ethereum 1.0 (one layer) .
These types of blockchains are:
- Decentralized: Yes. Because anyone in the world can choose to become a mining node. Thousands of miners around the world are involved in securing the Bitcoin and Ethereum networks. There is also no need to authorize yourself as a miner; it is completely trustless.
- Safe: Yes. Because every node in the network keeps a copy of the blockchain and verifies every transaction. Additionally, Proof of Work is designed to handle up to 50% malicious nodes.
- Scalability: No. With its security, every node in the network keeps a copy of the blockchain and verifies every transaction. While secure, it is inefficient, resulting in very low latency and throughput. For Bitcoin, that's about 7 transactions per second, and for Ethereum, it's about 15 transactions per second.
Safe and scalable
The right side of the triangle is a typical high TPS chain, such as Binance smart chain. They use a consensus algorithm called "Proof-of-stake-authority" in which 21 nodes are "elected" to generate new blocks. Every 24 hours, changed its name to BNBChiin on February 15th, and expanded from 21 nodes to 41 nodes. A new set of 41 nodes will be elected to generate new blocks within 24 hours.
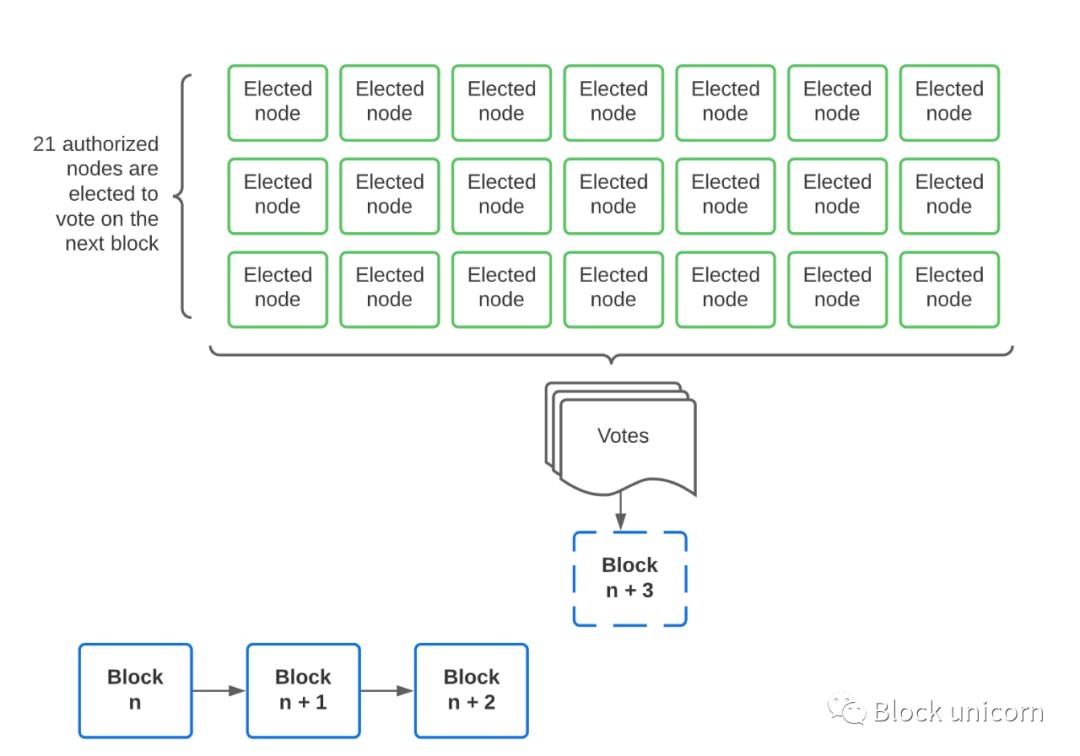
- Safe: Yes. Every "election" node is authorized, so we control the opponents in the system.
- Extensible: Yes. Since a small number of elected nodes produce new blocks at any time, we can achieve higher transaction throughput and lower latency, which means lower interaction fees than if every node had to verify every transaction .
- Decentralization : Not decentralized enough. With only 41 elected validators, it is much less decentralized than traditional blockchains. Additionally, each " Election " node is authorized, so we introduce trust into the system, making it less fragmented.
Scalable and decentralized
The left side of the triangle is the multi-chain ecosystem, Examples include Cosmos, Polkadot, and Avalanche. These systems have many independent blockchain networks that all communicate as part of a larger blockchain network.
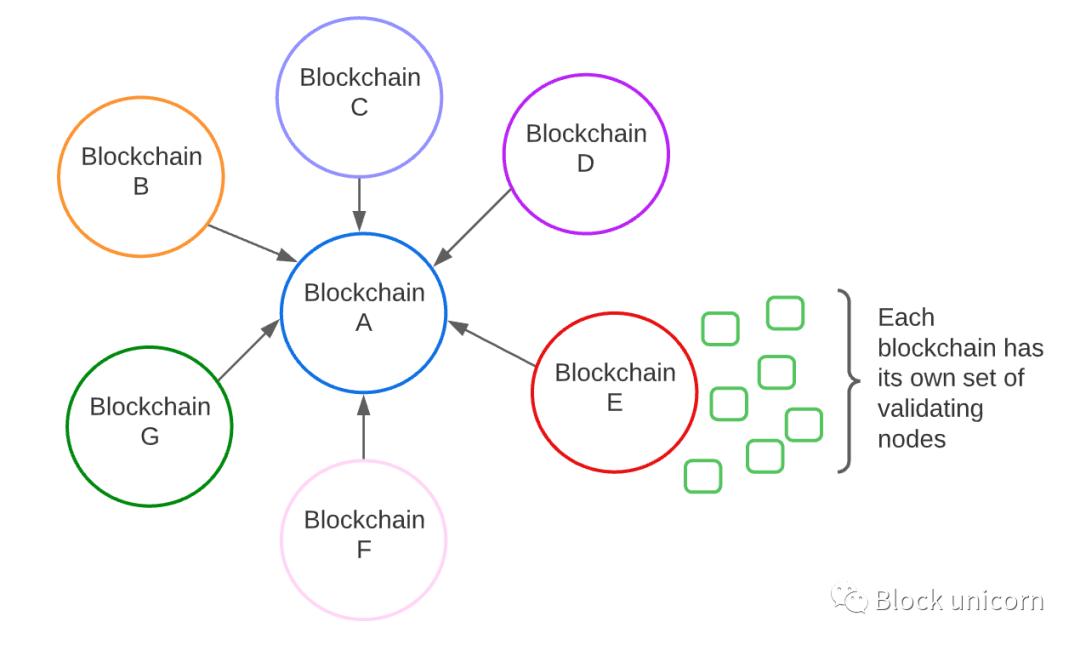
- Extensible: Yes. Since we no longer need to store all the state on a single blockchain, we can split the state across many independent blockchains, allowing for higher scalability than traditional blockchains.
- Decentralization: It depends. Each blockchain in the ecosystem has a set of nodes that validate the blockchain. Some chains in the ecosystem will have many validators (e.g. stablecoin chains that require decentralization), while others may have few or even one (e.g. enterprise chains that do not require much decentralization). So the degree of decentralization depends on which chain in the ecosystem we are referring to.
- Security: Not very secure. If one chain in the ecosystem is compromised, it could have a ripple effect on the rest of the system. For example, if chain B is attacked, and chains A, C, and D all depend on it, then other chains will also be affected.
As you can see, there are many different attempts at scaling blockchains, but it almost always comes at the expense of one of these three properties. Vitalik and the Ethereum community have been reluctant to make this compromise, and their goal is to get all three.
Before we look at how this is possible, it's important to understand another thing: Layer 1 scaling vs. Layer 2 scaling.
Understanding Layer 1 and Layer 2 Extensions
At the highest level, Layer 1 Scaling refers to extending the core blockchain itself. In contrast, Layer 2 scaling refers to moving transactions from the main blockchain layer into a separate layer that can communicate with the main chain.
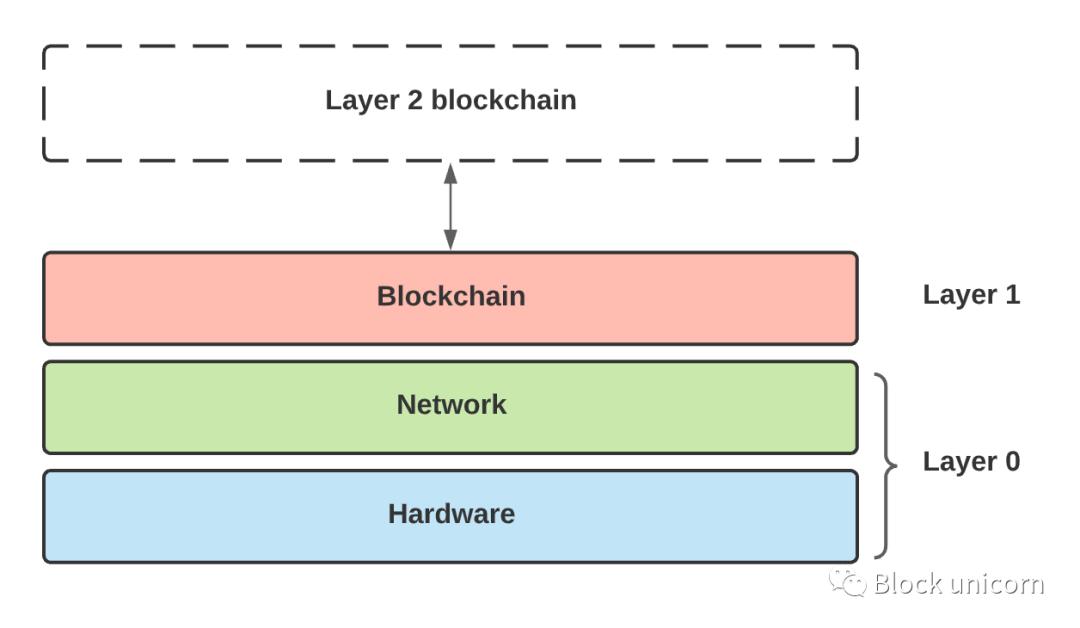
Ethereum wants to use both layer 1 and layer 2 solutions to solve the scalability trilemma, sharding is Ethereum’s layer 1 solution, while aggregation is a layer 2 solution for Ethereum.
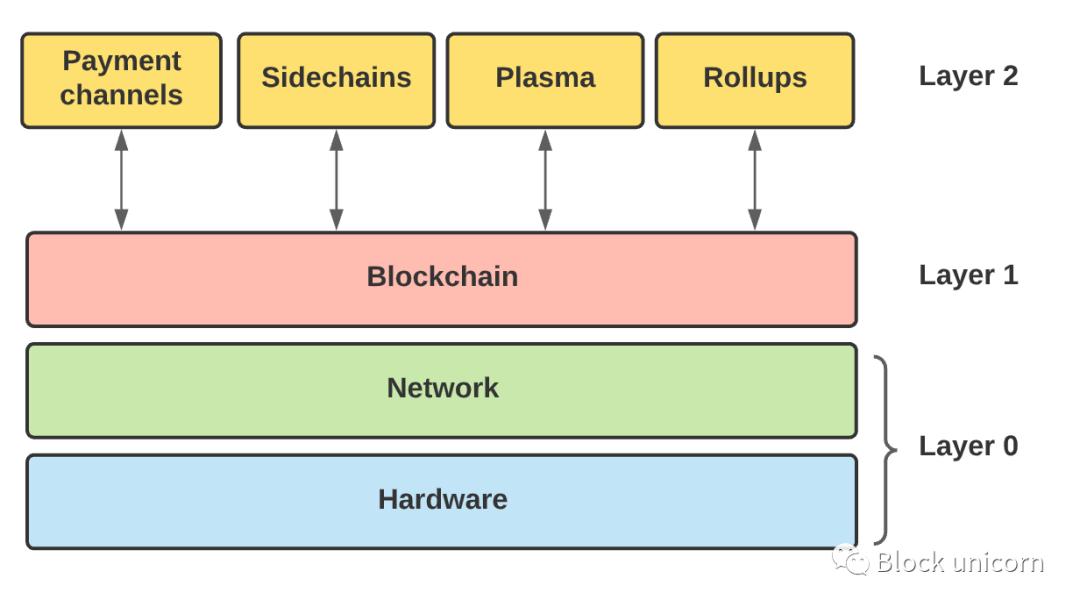
Ethereum's earliest layer-2 solution
But aggregation and sharding have to wait a while. First, we should document the layer 2 scaling solutions that Ethereum has explored in the past, and then finally come to the summary, the "holy grail" of Ethereum. After all, that's how engineering works—we come up with ideas, test them, and iterate until we find a viable solution.
State Channels
State channels have been around for a long time, so they are not something new. Here's a quick explanation of how they work. Let's say we have two people, Alice and Bob, who want to trade with each other. Alice pays Bob $1 every time she tweets. But since Bob tweets a lot every day, using Ethereum to do transactions would be too slow and too expensive.
Instead, they use "state channels":
- Alice in Ethereum's $500 is invested in the smart contract.
- Whenever Alice wants to give Bob $1, she signs a message stating how much she wants to give Bob how much. She keeps signing messages until Bob is ready to "cash out" his funds.
- Bob submits a new message indicating that he is ready to close the state channel. A smart contract on Ethereum verifies Alice and Bob's signatures, pays Bob the amount due, and returns the rest to Alice.

Note that only the first and last steps require us to transact on the blockchain, between these steps Alice and Bob can send each other Send an unlimited number of signed messages indicating payment. In this case, the Ethereum blockchain is only used as a settlement layer to process the final transaction of the one-time payment, which reduces the burden on the underlying blockchain.
The point is this: by opening up a channel for transactions outside the blockchain, we have dramatically increased transaction capacity and speed while keeping costs low. This is possible because:
- First, most transactions happen off-chain, which means that payments can be processed instantly because of the Off-chain updates do not require additional time to process and validate the blockchain network.
- Second, payments incur lower fees since we only need to make on-chain transactions when opening and closing state channels. This means that most transactions take place off-chain with much lower fees.
So why isn't this the final solution? Well, there are limits to what state channels can do.
For example, we cannot use state channels to transact with people who are not part of the state channel, and we are limited to the types of state updates possible in state channels. Complex applications like Uniswap cannot be used in state channels because when we swap two tokens on Uniswap, the smart contract automatically executes a series of intermediate steps to make the swap without authorizing the user on each step signature.
Another disadvantage of state channels is that they require us to lock liquidity in order to instantiate the channel and prevent a situation where a malicious counterparty may never actually pay the committed funds. This may be fine for a single channel, but when we try to make payments through a network of state channels, the liquidity locked in intermediate channels makes it quite "capital inefficient". Finally, state channels require someone who can regularly monitor the network (or delegate this responsibility to someone else). This keeps your funds safe, which adds another layer of complexity and inefficiency.
In summary, state channels are suitable for use cases where two parties need to transact quickly and cheaply over a period of time (such as a merchant and a customer). But given their limited use cases and capital inefficiency, we don't see state channels as the ultimate scaling solution for Ethereum.
Sidechains
Sidechains have also been around for a long time and are easy to understand . In short, a sidechain is an independent blockchain " pegged " to the main blockchain.
When we "hook" one blockchain to another, it means we can move assets between the two blockchains . The "one-way" peg is where we move assets from the main blockchain to the sidechain, and not the other way around. This is accomplished by "burning" tokens on the main blockchain by sending them to unusable addresses, and " minting" equivalent tokens on the sidechain.
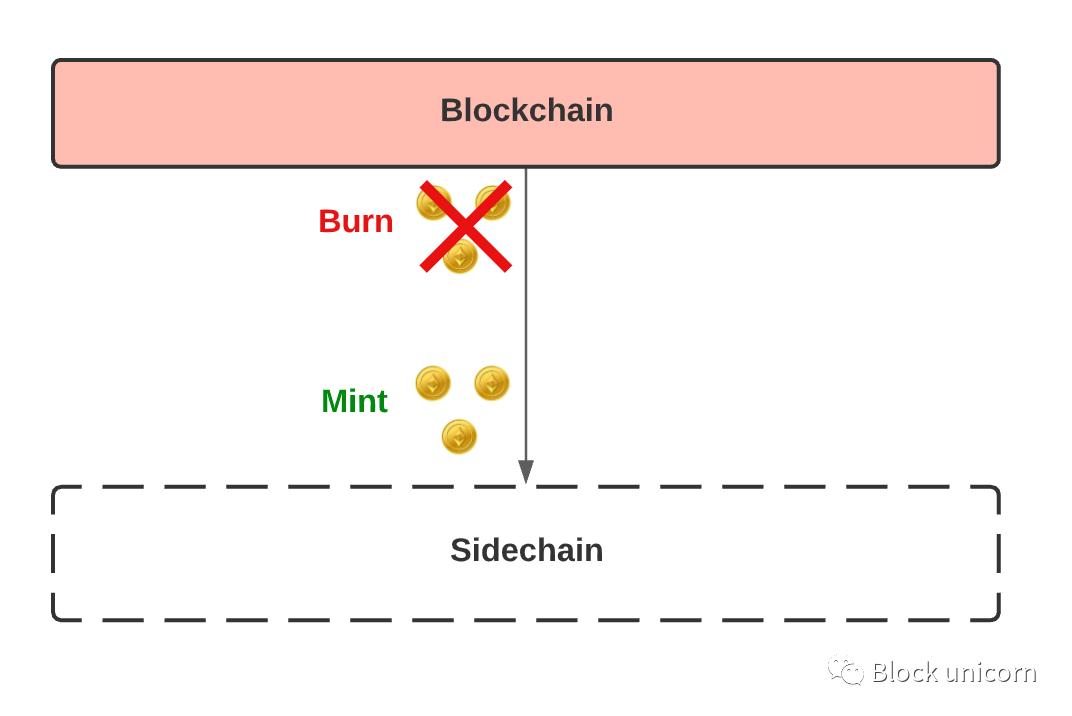
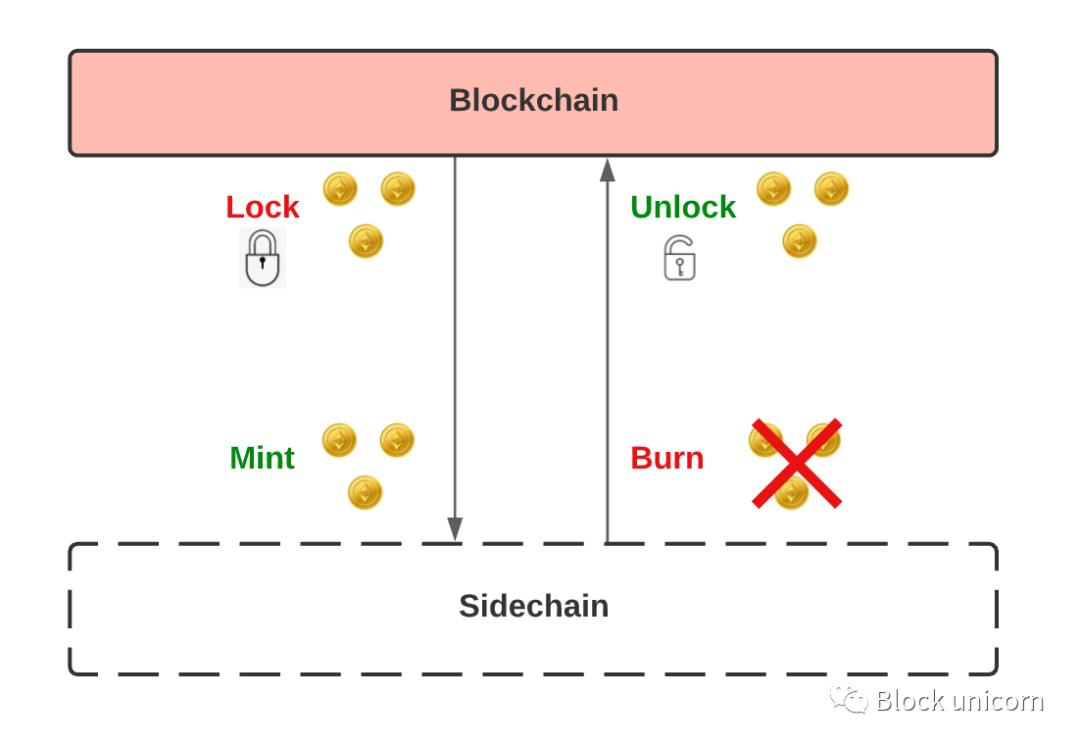
Then, a "two-way peg " is when we can move assets in and out of the main blockchain and sidechains. This requires " locking" our tokens on the main chain, and then " minting" an equal amount of tokens on the side chain. When we want to switch back to the original tokens, we "burn " the tokens on the sidechain and unlock the tokens on the mainchain.
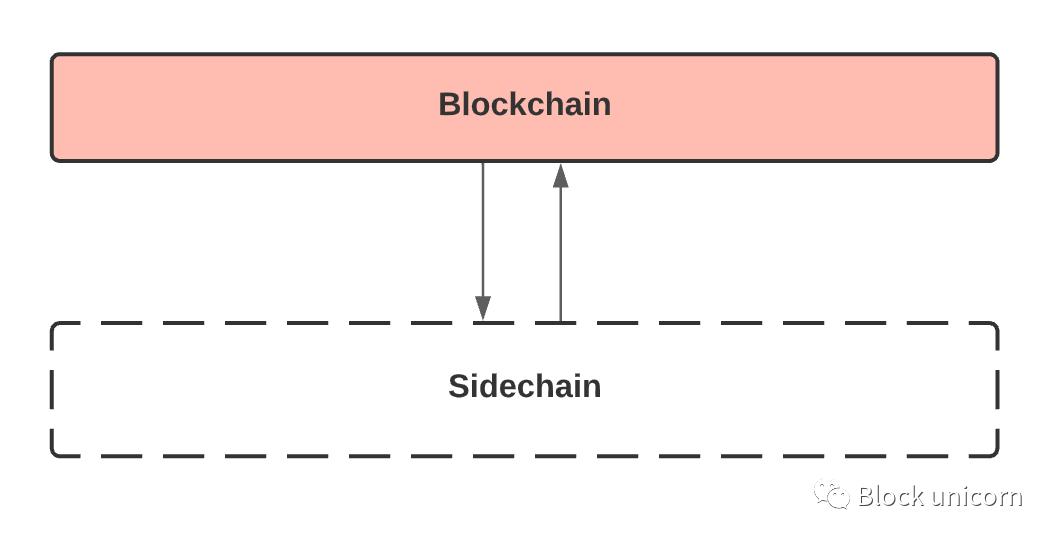
So, a sidechain is when we create a new blockchain that is bi-directionally pegged to the main blockchain. When we want to transact faster, we can transfer our funds from the main chain to the side chain and do the transaction there. Once done, we transfer the funds back to the main chain.
An example of a Bitcoin sidechain is the Liquid Network. The Liquid Network is pegged to Bitcoin, allowing faster and cheaper Bitcoin payments. Another popular example is Polygon, which is a sidechain pegged to Ethereum.
When users want to transact faster, they can lock up some ETH and create an equivalent amount of Matic tokens on the Polygon sidechain. On the Polygon sidechain, they can enjoy faster and cheaper transactions. When they complete the transaction, they can convert their Matic tokens back to ETH.
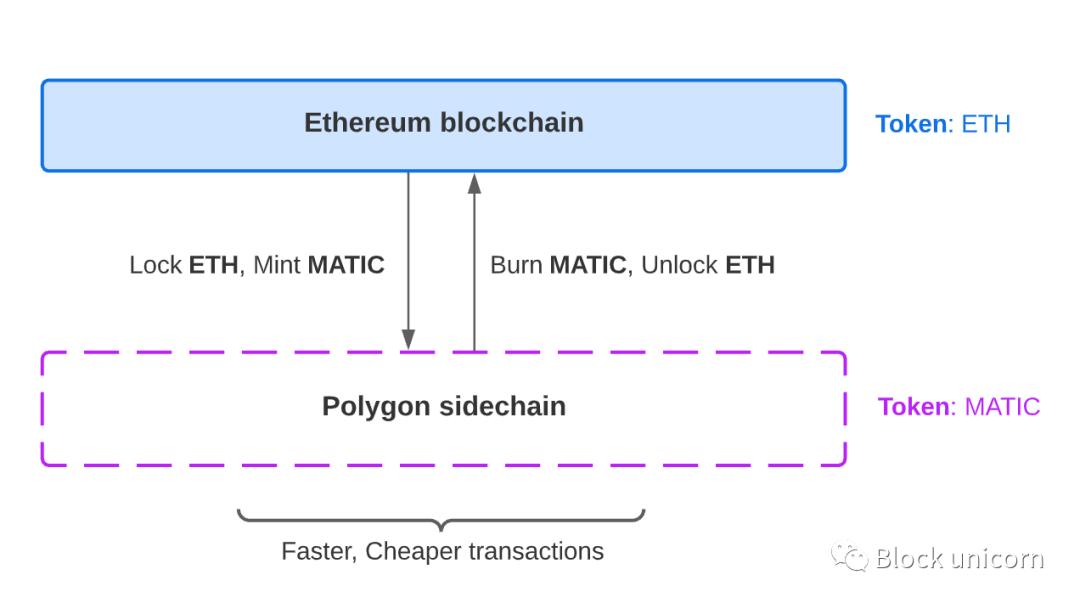
Note: Matic is technically not a sidechain as it periodically commits the state of the sidechain to Ethereum. Hence, they like to call themselves " commit chains ".
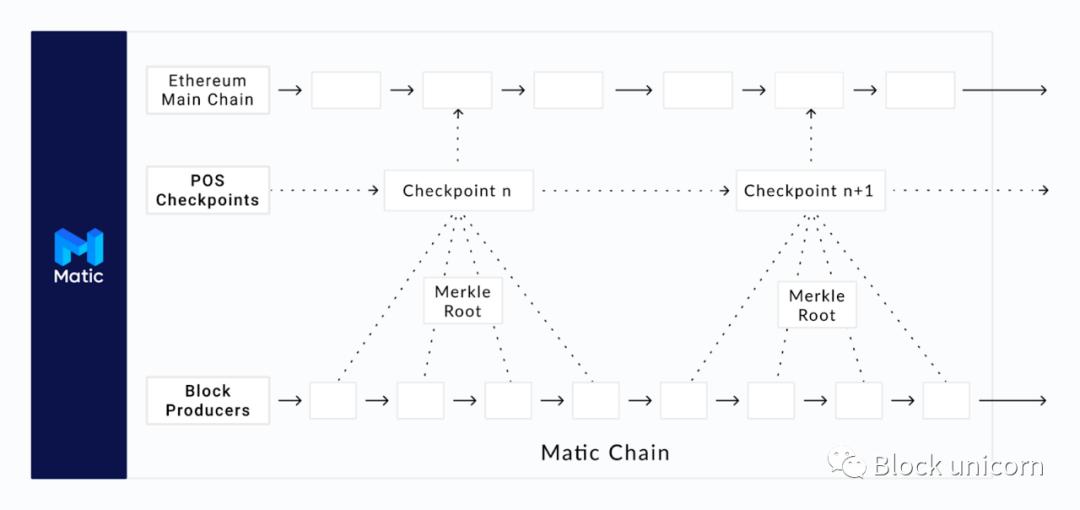
Overall, sidechains are scalable because they typically trade off decentralization and/or security by using different consensus algorithms that allow for scalability. Sidechains are a good stopgap solution for massive congestion on the Ethereum network, but Ethereum also doesn't see this as the ultimate scalability solution. As you read on, it will become clear why :)
Plasma
Plasma is Another "Layer 2 " solution that allows us to move transactions out of the base layer. Before we get into Plasma, it's important to note that Plasma has had several iterations over time, each with its own trade-offs. You can check out the Plasma world map, which lists the many different types of designs people have tried to create to solve the challenges presented by Plasma, there are many!
Of course, for the purposes of this article, I have to generalize the concept of Plasma without focusing too much on individual implementations. If you want to dig deeper, be sure to check out the world map. So, what is Plasma? Plasma is essentially a series of smart contracts (or "Plasma chains " ) that run outside of the main blockchain.

Plasma chains are like branches of a tree, Ethereum is the backbone, each Plasma chain is a branch, and each branch is considered to have its own blockchain history and computing blockchains. The " root blockchain " (i.e. the Ethereum blockchain) uses something called " fraud proofs " to enforce the validity of the state in the Plasma chain. Fraud proofs are a mechanism by which we provide certain data that anyone can use a mathematical proof to determine if the data is invalid.
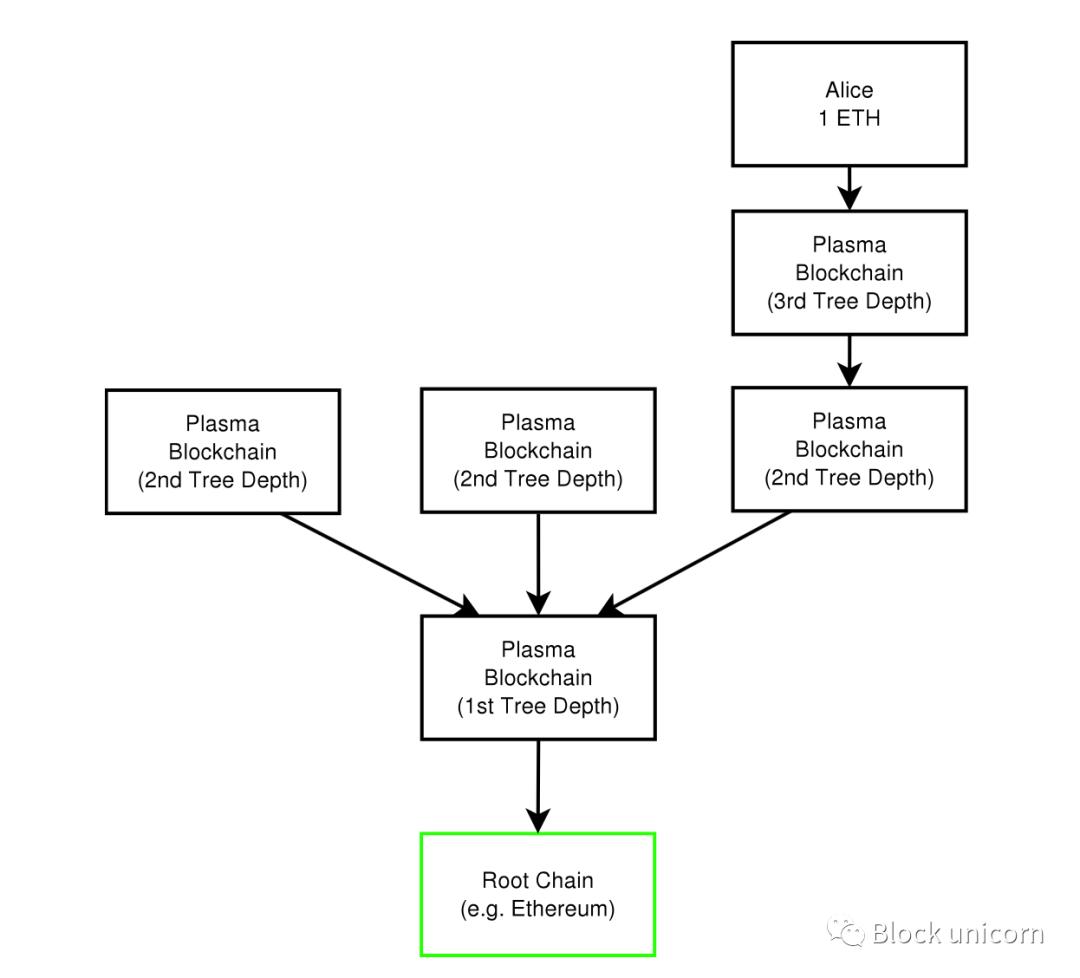
Each Plasma blockchain does not need to publish transaction data to the root chain. Instead, each Plasma chain has an "operator". This could be a centralized actor, a multisig representing multiple individuals, or even a committee that participates as an operator. The operator of the Plasma chain submits the Merkle root of the transfers that occur on the Plasma chain. NOTE: If you don't know how Merkle trees work, then I strongly recommend reading this explainer before proceeding. At a high level, Merkle trees allow us to take a large dataset (e.g., the transactions in a block) and produce a single root hash that represents the entire dataset.
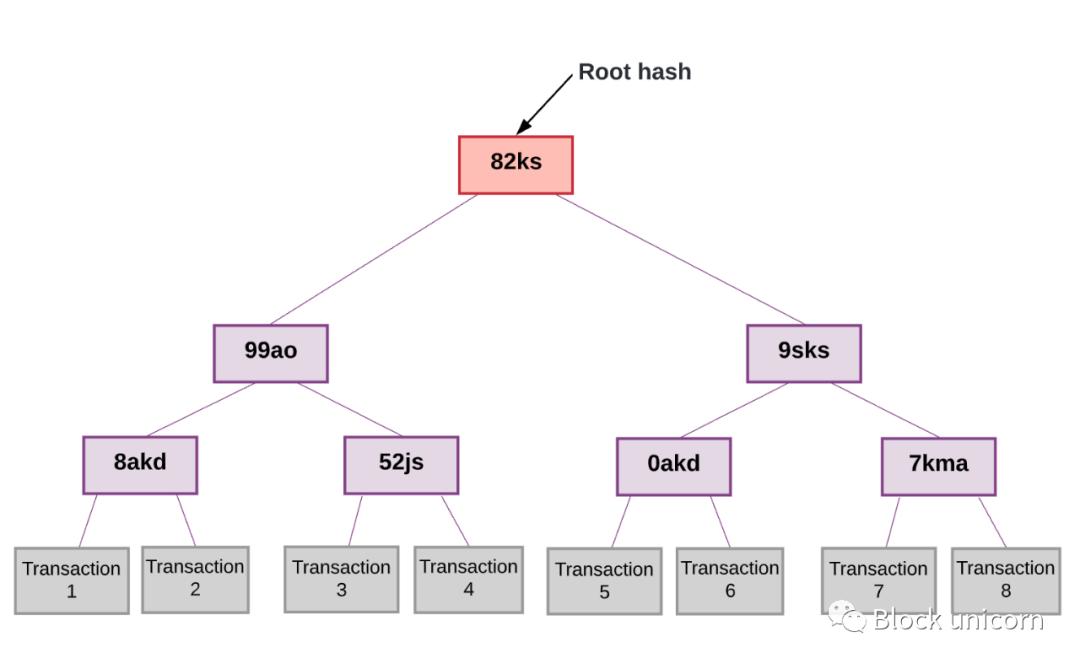
Later, we can easily prove that a piece of data from a large dataset (i.e., a single transaction from one transaction block) exists in that dataset simply by providing access to Branch of this data.
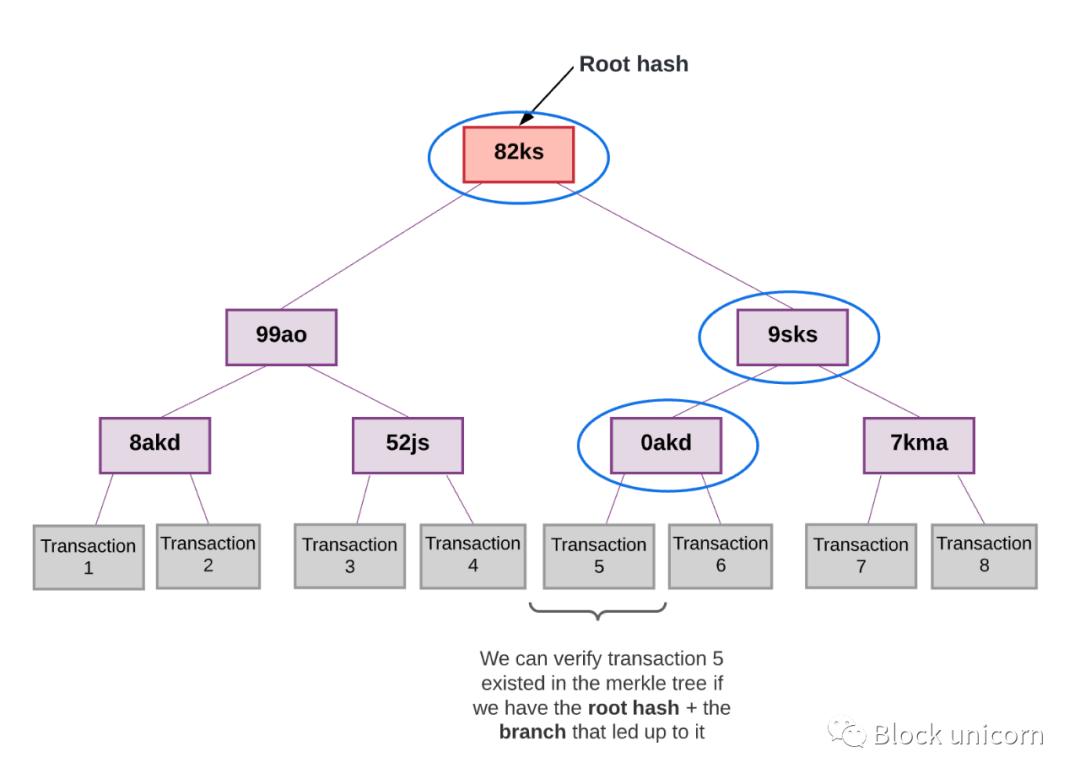
If someone tries to prove the existence of a fraudulent transaction, the hashes will not match and we will know immediately.
Okay, back to Plasma.
Each Plasma chain is committing the Merkle root of the transfer that happened on it. When a user later tries to move their asset from the Plasma chain back to the root chain, the user can submit the Merkle branch of the latest transaction that sent the asset to them (recent enough for us to know the current balance is waiting on Plasma). This starts a challenge period where anyone can try to prove that a user's Merkle fork is fraudulent. If a Merkle branch is fraudulent, a fraud proof can be submitted. Since the root blockchain only tracks Merkle roots, it has to deal with far less data than those transactions that occur on the main chain. This significantly reduces the amount of data stored on the root blockchain and allows us to scale the root chain. In addition, if a particular Plasma chain is maliciously attacked, people can " massively withdraw" from the corrupt child chain.
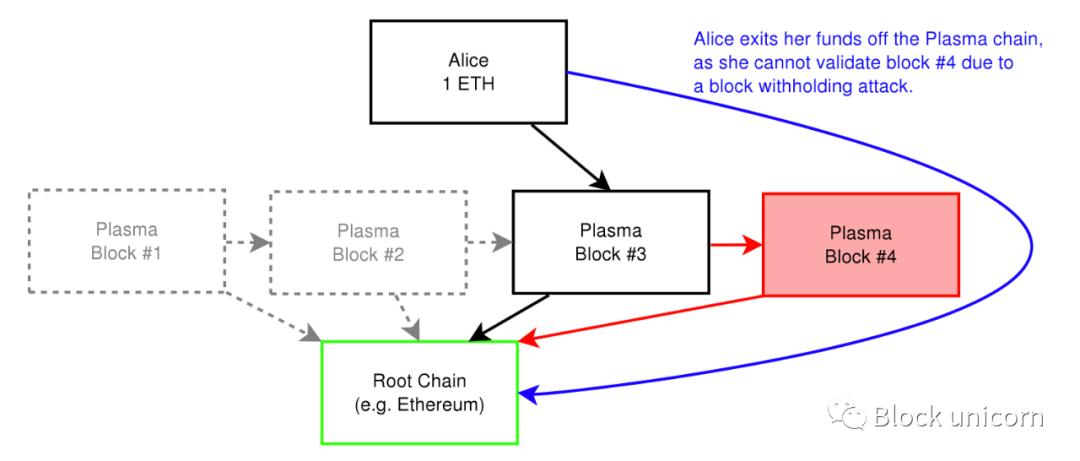
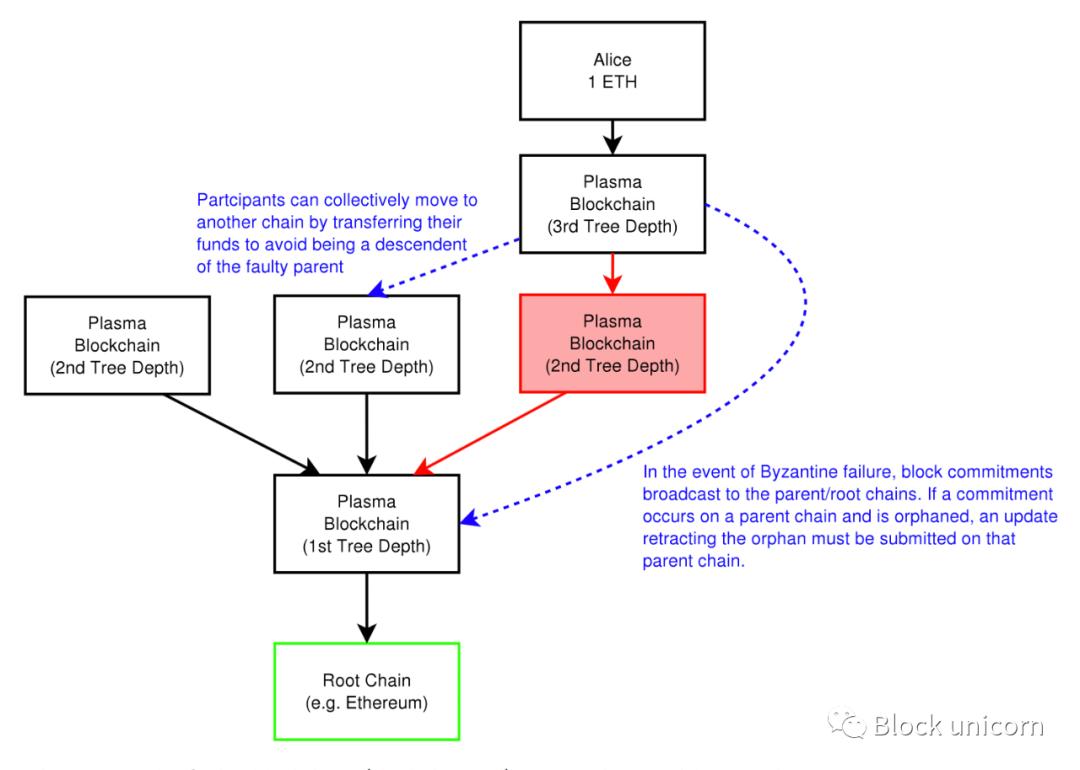
Plasma is more beneficial than state channels because you can send assets to anyone, whereas with state channels you can only transact with people in the state channel. Also, the benefit of Plasma over sidechains is that Plasma chains are secured by Ethereum.
The fundamental difference between the two (Plasma vs. sidechains) is that sidechains have their own security model. They have their own consensus mechanism and a separate set of nodes to validate the state. Even if the sidechain is attacked, nothing will happen to the mainchain and vice versa. In case of an attack on the side chain, the main chain cannot protect users.
On the other hand, etc. Plasma has a dependent security model, each Plasma chain can use its own mechanism to verify transactions, but it still uses the Ethereum blockchain The blockchain acts as the ultimate arbiter of truth. In the event of a Byzantine attack, Plasma users can exit to Ethereum.
But Plasma has several drawbacks that make it a lackluster scalability solution.
First, when users want to transfer their assets from the Plasma contract to the Ethereum main blockchain, they need to wait 7 days. This is enough for people to verify that the withdrawal transaction is not fraudulent. If so, they can construct fraud proofs using Merkle trees on the Plasma chain.
Secondly, every Plasma chain needs an operator to post Merkle root commitments to the main chain. This requires us to rely on a third party to accurately publish the Merkle root commitment to the chain. Unfortunately, operators can perform so-called "data availability attacks", where they refuse to publish certain transactions to the main chain for malicious reasons.
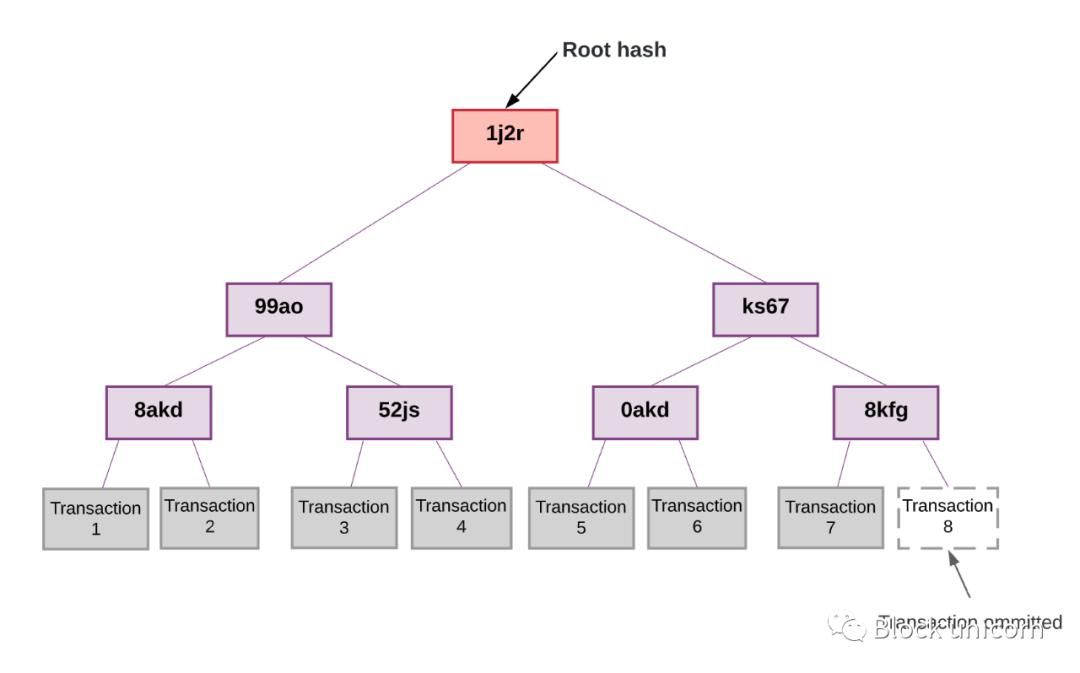
In this case, the operator can convince the network to accept invalid blocks without being able to prove invalid blocks. This prevents other users from knowing the exact state of the blockchain. This also prevents people from creating blocks or transactions because they lack the information to build proofs. Unlike fraud, data availability attacks are not uniquely attributable. We have no way of knowing that an attack is happening.
Operators can also operate maliciously in more explicit ways, such as by submitting fraudulent transactions. In this case, people can "massively withdraw," as mentioned above. But these have proven to be far more difficult to implement in practice. If many users want to withdraw on a large scale, it may cause congestion on the main chain, and users may not be able to withdraw in time, resulting in loss of funds.
Third, Plasma requires the owner of the transaction asset to be present. This ensures the security of the Plasma chain as it effectively makes transactions (such as sending ERC 20 tokens to approved addresses) impossible without the consent of the owner. Plasma works best for simple transfers, but as transactions become more complex, the design space becomes irregular.
For the above reasons, Polygon and OMG Networks initially pursued a Plasma architecture for scaling, but then abandoned it. It is in this case that, after various solutions have been proposed, we have a summary.
Aggregation
Like state channels, sidechains, etc. Plasma, aggregation is " Layer 2" solutions. In fact, rollup is very similar to Plasma in that we batch transactions off-chain and publish updates to the main blockchain. However, the key difference is that with aggregation, we also publish the transaction data for each batch of transactions on-chain. With Plasma, we only publish Merkle roots.
In other words, with aggregation, we do transaction processing off-chain, but we publish transaction data on-chain. The amount of data we publish on-chain is the minimum amount required to locally validate aggregated transactions. By putting data on-chain, anyone can detect fraud, initiate a withdrawal, or start generating transaction batches themselves. Therefore, rollups give us higher security guarantees than Plasma chains or sidechains.
Another key difference between rollups and Plasma is that we don't have to worry about data availability. After all, we publish transaction data to the main chain. This is a huge win.
Using rollup, we effectively run a version of the EVM inside the rollup layer. This means that any possible transaction on Ethereum can be executed in the rollup.
This begs the question: if we still publish transaction data on-chain, how does this scale layer 1? Isn't scalability still limited by the data bandwidth of the main chain? Yes. The key here is that we get 5x to 100x scalability with rollups, but not infinite scalability. Rollups also use a lot of fancy compression tricks to minimize the amount of transaction data we post on-chain, so much less data is stored on-chain than it would be otherwise.
At the same time, we outsource all the heavy lifting of off-chain transaction execution to Rollup. Recall that during transaction execution, transactions must be processed by the Ethereum Virtual Machine (EVM) and interact with state (such as storage, account balances, etc.). This is expensive.
However, for rollups we shift this execution to the rollup layer by running a version of the EVM in the rollup - so we're still doing the same execution , but the gas cost of the aggregation layer is much cheaper than that of Ethereum.
A closer look at summarization
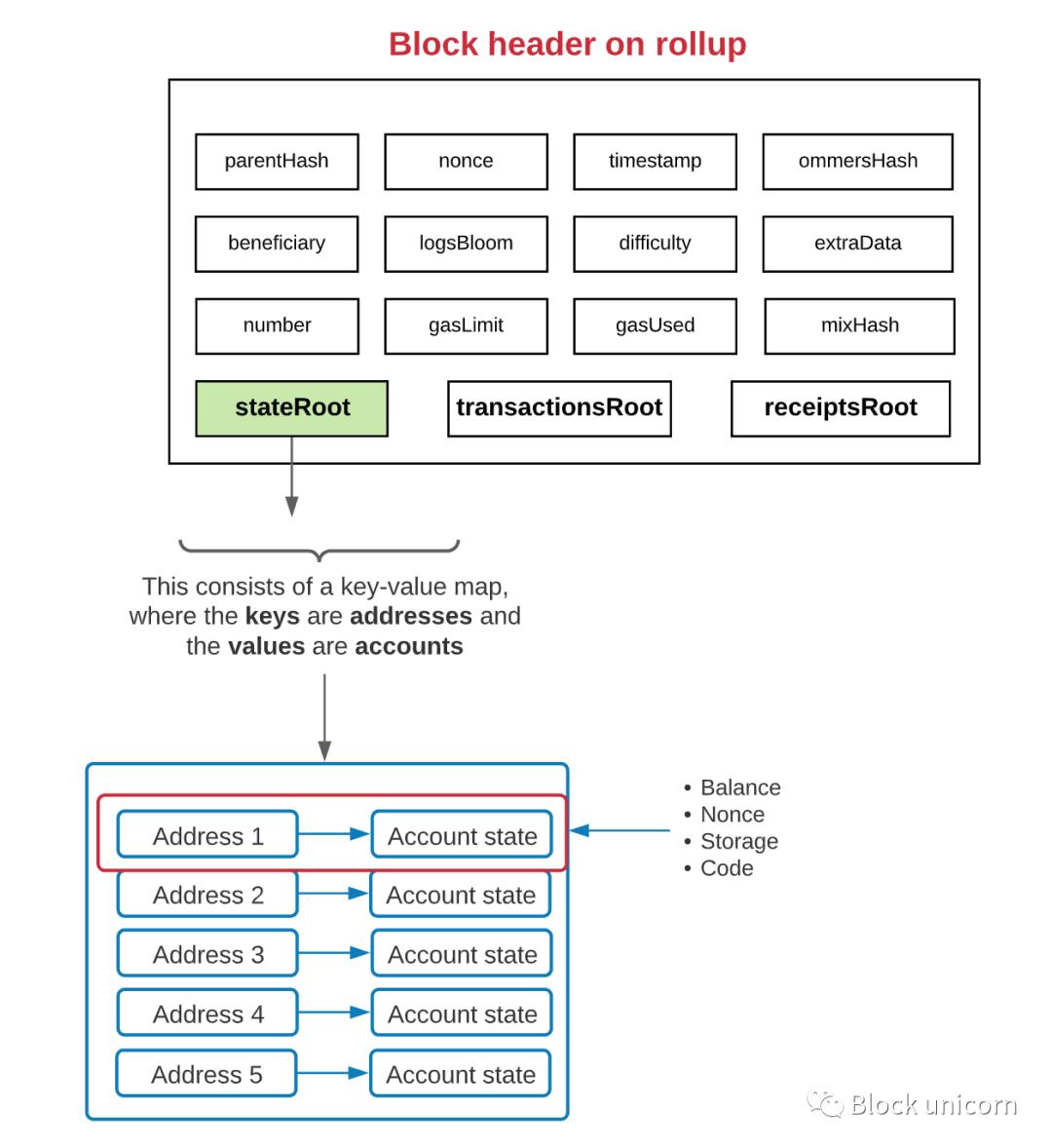
Now, let's see how summarization works behind the scenes . There is a "summarization contract" on the main chain to maintain the current state of the summarization layer. This includes the account balances of users making transactions on it and the smart contract code of the contracts that exist within it. In short, the rollup contract keeps track of the "state root" of transactions in the rollup layer.
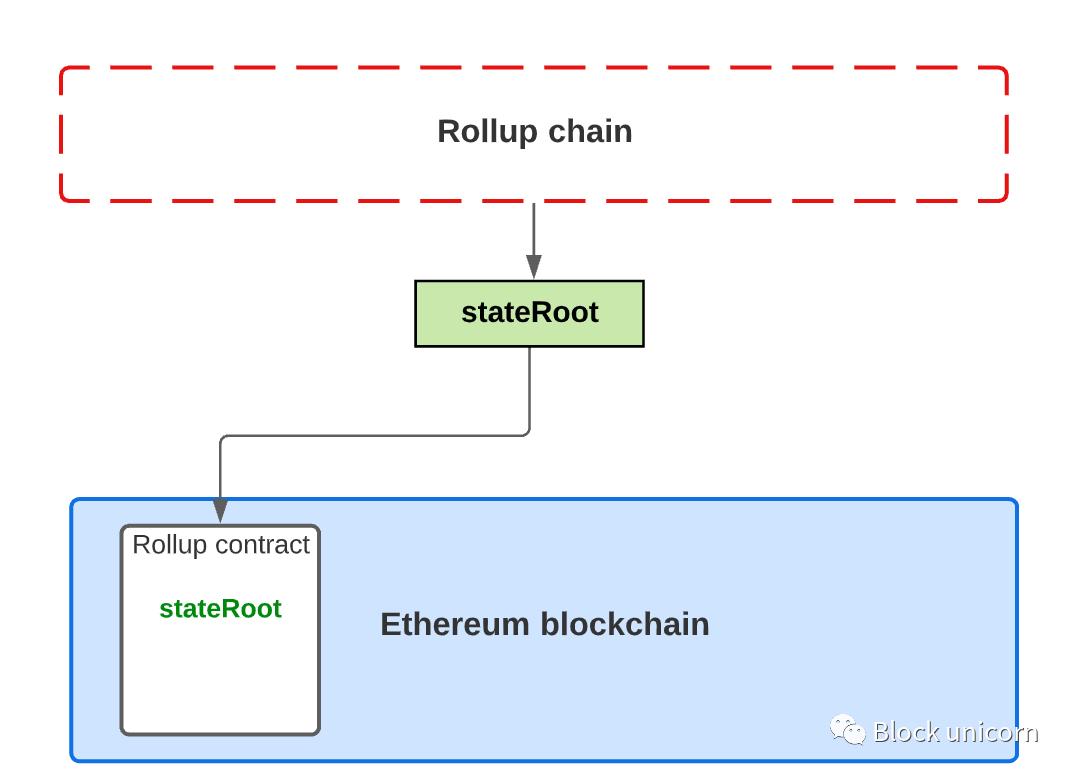
The "state root" consists of a key-value map, where the keys are addresses and the values are accounts. Each account has up to 4 properties: balance, nonce, code (only for smart contracts), and storage (only for smart contracts).
A state change occurs when a transaction occurs at the rollup layer. Of course, this means that the state root also needs to be updated. But instead of updating the state root for each transaction, transactions are "batched" to a summary contract on the main chain. The batch will include a compressed form of the batch's transactions and an updated state root representing the processed data for the batch's transactions. The rollup contract on the main chain checks whether the previous state root in the batch matches its current state root - if so, it switches the state root to the new state root.
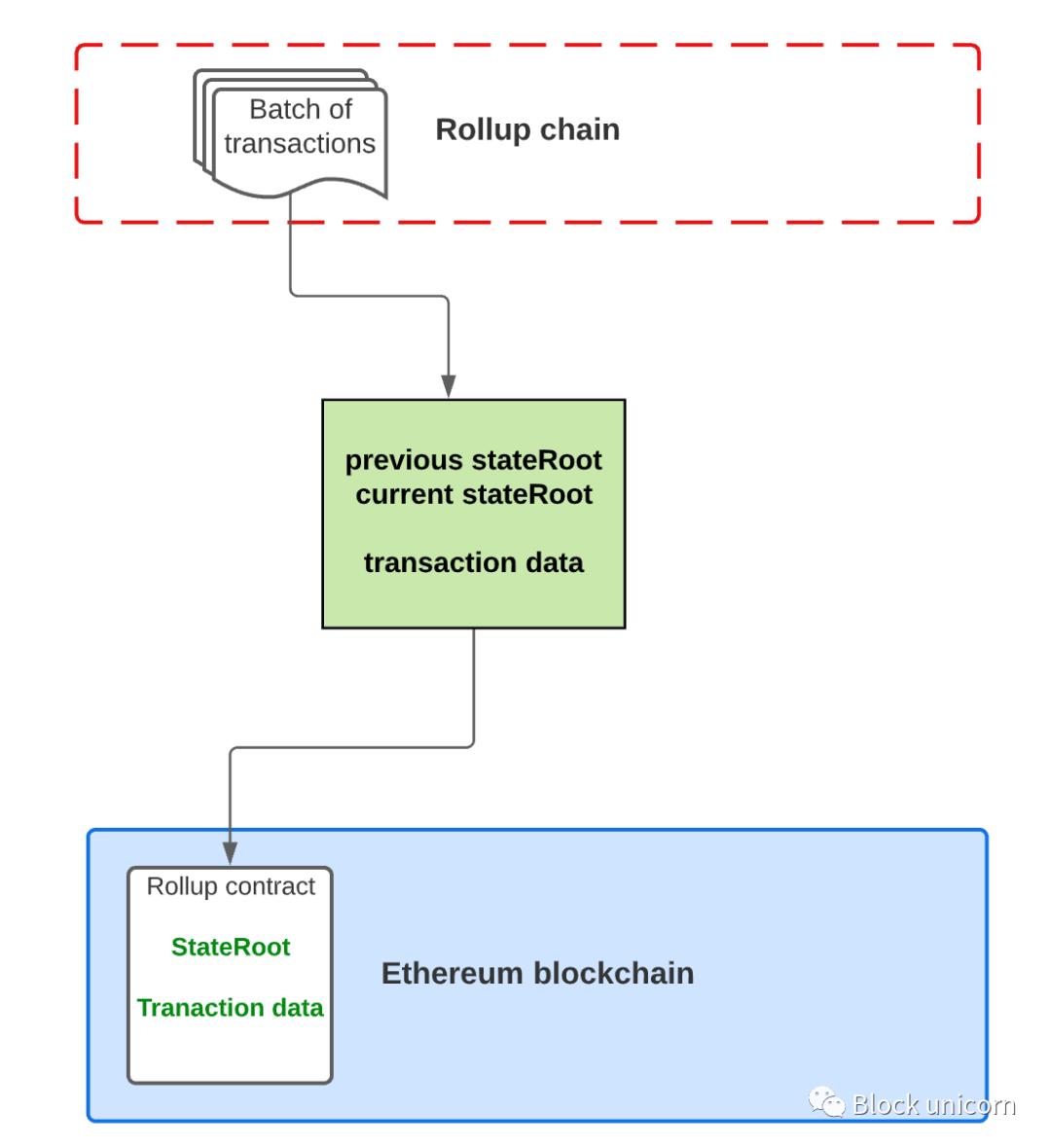
Since the published transaction data is not actually interpreted by the EVM, we do not access or write to the state - which is too expensive. Instead, we post the compressed transaction data to the aggregate contract as the "calldata" parameter.
That's why this is neat, in Solidity calldata (which is a way of storing data structures) is the cheapest form of storage. In fact, the parameters passed as calldata parameters are not stored in the state of Ethereum at all, which means we avoid a lot of gas costs. At the same time, Ethereum nodes can still store transaction data (in the history log) when creating blocks.
Savvy readers may wonder what the difference is between Plasma and Rollup. This is the key difference: with aggregation, we publish transaction data on-chain along with the state root. With Plasma, we simply publish the state root of the transaction.
Unlike Plasma, where we have an operator that publishes the Merkle root to the root chain, rollups allow anyone to publish a new batch of transactions to the on-chain rollup contract, which we'll explore in more depth later.
Again, this begs the question: since we are only posting transaction data to the main chain and not executing transactions on the chain, how do we know Are the transaction data and state roots on-chain not fraudulent?
Input: Optimistic rollups and zero-knowledge rollups, each with their own way of processing and verifying correctness of batches.
Optimistic Aggregate
You can probably guess what an Optimistic Aggregate is from the name, when a When batches of new transactions are "rolled up" to the main chain, the state root and hash of each batch are published, but we don't actually verify that the transactions were executed correctly, at least not when they were published. In this way, we "optimistically" publish new state roots and transaction data to the summary contract on the main chain. When someone posts a new state root to the main chain, the rollup smart contract simply takes their word for it. If someone discovers that an invalid state transition was issued to the aggregate smart contract, they can generate a "fraud proof". Fraud proofs include:
- Proof of a "pre-state", or, how things were before a transaction was applied
- Proof of "post-state", or, how state should be handled after applying a transaction
- Proof of transaction applied during state transition< /p>
The workflow is simple: this fraud proof is published to the summary contract on the main chain. The proof of contract verification is then aggregated and transaction logic is applied to the pre-state. Then, it compares the result with the post state. If there is a mismatch, it proves that whoever issued the batch did not apply the transaction correctly. The smart contract then reverts that batch of transactions and all subsequent batches.
Anyone who publishes a batch to the main chain must deposit a security deposit for this, so if they act maliciously and get caught, they may was "forfeited".
ZK Summary
If optimistic summary uses "innocent until proven guilty" mentality, then ZK summarizes the mentality of "do not trust, verify". With ZK rollups, each batch contains a cryptographic proof, called a ZK-SNARK, that proves that the state root was the correct result of executing that batch of transactions. A ZK-SNARK proof is a hash representing the change in the state of the blockchain after a transaction is executed in the zk-rollup layer. This proof of validity is published to the rollup contract, so anyone can use it to verify transactions in a specific batch on the rollup layer. The magic here is in the way ZK-SNARKs work. They allow us to generate proofs of the underlying data without revealing the data. Anyone can later verify that the data exists, even if they don't have access to the data itself. The mathematical basis of ZK-SNARKS is complex and beyond our scope, but if you are curious, I encourage you to go to Google or YouTube and spend some time to understand how they work.
Which is better?
The obvious next question is...which is better? Hard to say. Each has advantages and disadvantages, let's take a look at it next.
Cost
"Cost" in the abstract doesn't make a lot of sense in , but when we break it down, the performance of optimistic and ZK rollups starts to diverge.
Gas cost for publishing new batches on the chain: Optimistic rollup costs less. We optimistically release new state roots and data, so it's an easy transaction. ZK rollups are more expensive. When we release a new batch on-chain, we must verify the ZK-SNARK proof of validity. This is computationally more expensive.
Gas cost per transaction published on-chain: optimistic aggregation is more expensive. We must publish enough data on-chain to verify the fraud proof later. ZK rollup costs are lower. We can omit most of the transaction data, since the proof of validity is sufficient for anyone to verify the correctness of the batch.
Off-chain computing cost: Optimistic aggregation costs are lower. We only publish new state roots, not execute/validate transactions. That said, we still need someone to watch the creation of new batches and the execution of new transactions to ensure that the batches are correct. ZK rollups are more expensive. ZK-SNARKs are computationally expensive (20 to 1000x more expensive, although it continues to get cheaper with innovation).
Sidenote: Although ZK-rollups are more expensive to compute off-chain, it is also important to consider that off-chain gas prices are much lower.
Speed
Optimistic aggregation is slow. Typically, users have to wait about a week before they can withdraw their assets. This may give someone enough opportunity to issue proof of fraud if a user tries to withdraw tokens on the rollup layer that they don't actually own.
ZK sums up quickly. Users typically wait less than 10 minutes to withdraw their assets. We just have to wait until the next batch to process withdrawals, since all aggregated statuses are already verified.
Side Note: There are ways to bypass this one week waiting period by using Quick Withdraw. This is done through liquidity providers who maintain a "cookie jar" of funds on the main chain. When users quickly withdraw funds, they give the liquidity provider an IOU for the funds in the pool, and they get paid (fee) immediately by the liquidity provider on the main chain.
Later, when the one-week period ends and users get their assets back from the aggregation layer, users can send the funds owed to them to liquidity providers. Liquidity providers can even choose to run a validator node to verify users’ transactions on the rollup before releasing funds to them on the main chain, further reducing their risk. However, this "quick withdrawal" scheme is impossible for NFTs, since only one of any NFT exists, and liquidity providers cannot create identical NFTs on-chain.
complex
Optimistic aggregation is simpler, The concept of fraud proofs has been around for a long time, so the solutions are relatively simple. ZK rollups are more complex, ZK-SNARKs are new and mathematically complex.
Broadness
Optimistic summarization is easier Broadly, engineers have built an EVM-compatible virtual machine called OVM (Optimistic Virtual Machine), which allows optimistic rollup to process any transaction that can be processed on Ethereum. ZK rollups are harder to generalize. Proving general EVM execution using ZK-SNARKs is much more difficult than proving simple computations such as value transfers. That said, there is a lot of innovation happening in this space. In fact, StarkNet alpha introduced a new programming language called Cairo, a Turing-complete ZK validator on Ethereum that allows us to verify general-purpose computing smart contracts.
Scalability
Optimistic Aggregation Scalability is poor. When we publish data on-chain, it usually includes some state (such as transaction details) and witnesses (such as digital signatures proving the consent of the transaction parties). With optimistic rollups, we have to publish a witness for every transaction so people can later prove fraud. Witnesses take up a lot of storage space, 3-10 times that of transaction data. ZK rollups are more scalable: we don't need to include witnesses for every transaction because all digital signatures are verified when computing ZK-SNARKs. Instead, we only need one witness per batch, which greatly reduces the data stored on-chain.
Safe
Optimistic summaries are less safe , optimistic rollup relies on cryptoeconomics to ensure the security of the chain. In other words, they must incentivize people to watch batches posted on-chain and detect fraud. ZK rollups are more secure, ZK rollups rely on mathematics, they do not require incentives. They use cryptography rather than cryptoeconomics. So, now that we've broken these down, which is better? Still hard to tell, but it's a testament to the great work done by the engineers behind these programs. We have teams like Optimism and Arbitrum working hard on optimistic rollups, which are already available to Ethereum developers. We have companies like StarkWare and Zksync bringing general purpose ZK-rollups to Ethereum. Both solutions are in their infancy. But optimistic rollups are closer to adoption because they are less complex and can be used for general-purpose computing today. On the other hand, ZK rollups will take some time to catch up, but many engineers will consider ZK rollups to be a superior technology. After all, they rely on mathematics rather than cryptoeconomics, and they are more scalable than optimistic rollups. That said, the best technology doesn't always win. What we cannot ignore is that once a technology becomes entrenched, it is very difficult to replace. Optimistic rollups are definitely ahead - so only time will tell which will "win" in the long run.
The Smartness of Aggregation
Before we discuss some of the persistent challenges of aggregation, let Let's take a look at the compression tricks used by Aggregation to be so efficient.
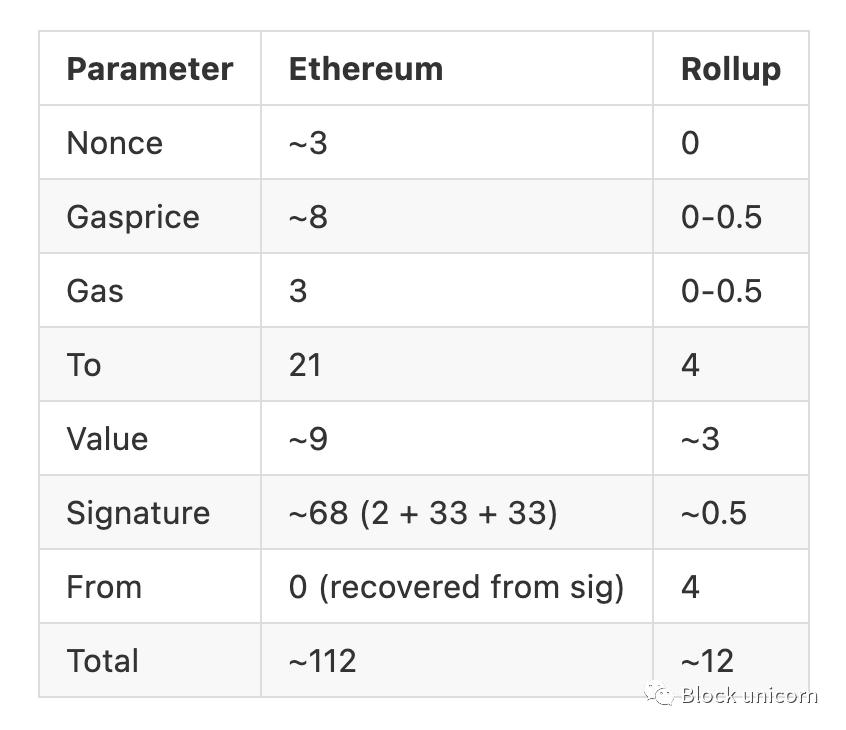
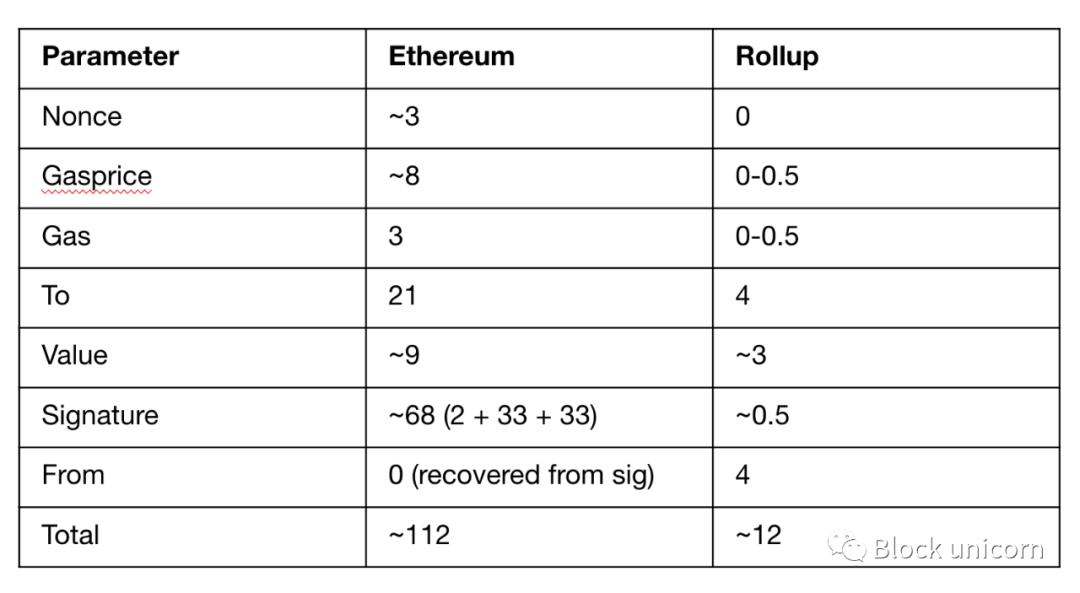
Nonce: In typical Ethereum transactions we include nonces to prevent double spend attacks. Rollups omit them entirely, since they can be recalculated using the previous state of the blockchain. In this way, summarization replaces data with calculations whenever possible.
Gas price: Instead of denominating in gwei (where 1 gwei is 10^-9 ETH), it is better to limit the Gas price to a fixed price range, thereby significantly Reducing the amount of storage required to record gas prices in transaction data really adds up!
Fee: Same as above.
To: An address is 20 bytes long, plus 1 byte for RLP encoding. A summary can store a mapping of indices to addresses, rather than including addresses, and only include indices in the "to" field (eg, 1234). It's like leaving the coordinates to the destination instead of rendering the whole location itself.
Value: The "Value" field is 9 bytes because ETH and ERC-20 tokens have a maximum of 9 decimal places. Aggregate can instead limit the value to a maximum of 3 decimal places, saving us 6 bytes. Looks very functional!
Signatures: As mentioned above, digitally signed "witnesses" take up a lot of storage space. Rollups can use BLS signatures (an algorithm for signature aggregation and key aggregation), which allows us to aggregate many signatures into one, which saves a lot of storage space!
Let's put this all into action, using all these compression tricks, how many bytes can we save for ETH transfers? A typical ETH transfer takes 112 bytes, but with all these compression tricks? At only 12 bytes, this is almost a 10x improvement in efficiency! ZK rollups can get more optimizations than optimistic rollups because they perform off-chain transaction validation before publishing transaction data to the main chain. They also don't need to include a "validation" part of the transaction data; a proof of validity is sufficient. All ZK Rollup needs to store is the data needed to compute state transitions. So it's important to note that rollups are not only efficient because they move computation off-chain, but also because of their very clever data compression tricks.
Rollups are not quite the "holy grail"
But don't get too excited, although rollups are very There is hope, but there are still a lot of kinks to be ironed out, here are some challenges you should be aware of.
Scalability has a ceiling
So far you have learned about rollups and other The main difference between layer 2 solutions like Plasma and sidechains. As you will recall, rollups move computation off-chain, but store data on-chain. This can be very helpful for troubleshooting data availability issues. But since we store transaction data on-chain (albeit in a very compressed form), we are still limited by Ethereum's storage capacity. We can do some rough math to see what the theoretical TPS would be using rollups.
Ethereum block gas limit: 12.5 million gas
Data cost per byte stored on the chain: 16 gas
Maximum bytes per block: ~781,000 bytes (12.5 million gas / 16 gas per byte)
Data required for ETH transfers using rollup Bytes: 12 bytes (see math in previous section)
Transaction per block: ~65,000 (~781,000 bytes per block / 12 bytes per ETH transfer)
Ethereum’s average block time: 13 seconds
Transactions per second: ~5000 TPS (about 65,000 transactions per block/13 seconds per block)< br>
Of course, this math assumes that all transactions in a block are ETH transfers, and that there is nothing in a block other than batch aggregate transactions something, it's highly unlikely. Most blocks will contain various transactions, including some layer 1 transactions that will cost more than 16 gas. Also, if these are ZK-rollup batches, the cost of verifying the SNARK proof on-chain will not be included, which is roughly 500,000 gas. Still, this gives you a starting point to use aggregated TPS, 5,000 is nowhere near the 65,000 TPS Visa apparently has, but it's much better than today's TPS for Ethereum.
Broken Mobility
Rollup technology was created as a stand-alone project and Not created by the Ethereum protocol itself. So there will be several different aggregation techniques in parallel, and this is where the liquidity breaks. As liquidity moves from the main chain to the aggregate, it "breaks" the liquidity of the different aggregate networks. Although once there are mechanisms for communicating across aggregates this could be solved, some clever engineers are already working on those!
Reduced Composability
One of the main benefits of building on Ethereum is that Combination. Every new protocol built on Ethereum is like Lego bricks that other protocols can easily build on top of. For example, this is what makes DeFi so powerful. It allowed us to create money Lego bricks. We lose some composability when applications and liquidity move to rollups. After all, passing messages and transactions between the aggregation layer and the main chain is not as easy as it is in the context of the base layer. But it may only be a matter of time before this problem is resolved. I can certainly see a world where smart contracts that exist on different aggregates can still communicate with each other. As always, we're only a few bright engineers away from solving these problems.
Centralization
We neglect to discuss who is actually responsible for posting new batches to the main chain part, so let's get back to that topic. Most rollups rely on a "sequencer" to do the job: a sequencer is a node that batches transactions and publishes the results to the rollup contract on-chain. For Arbitrum, Optimism, and StarkNet, the sequencer is a single node running by itself.
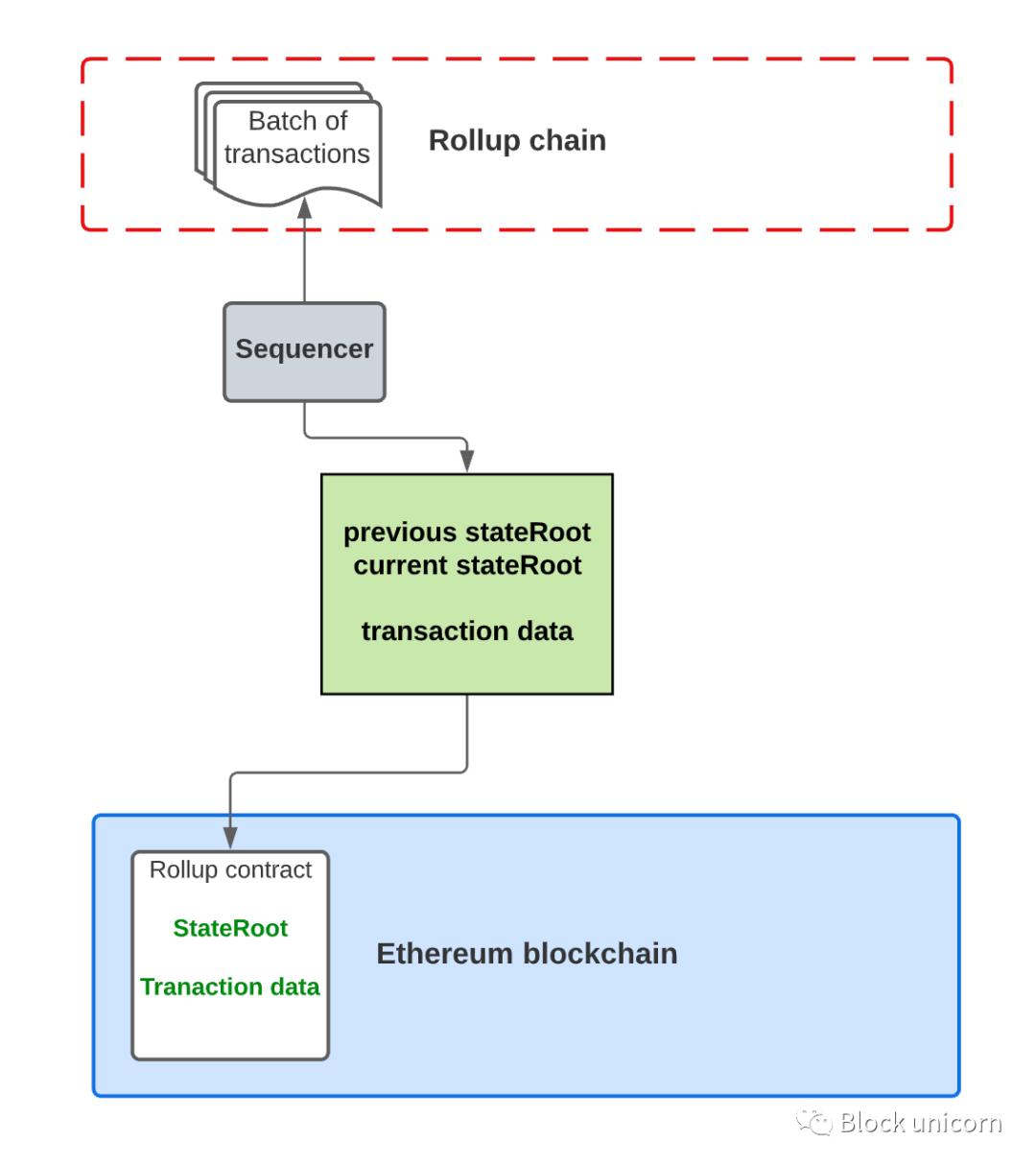
I know. "Decentralization" is the core of the blockchain. Although it is very efficient, it is obviously very centralized. What if the sequencer fails or censors the transaction?
Well, it's not that simple. The reason these projects are currently taking this route is because it is easier and faster to iterate using this method. To reduce the risk of centralization, over time most rollups would like some kind of decentralization of the sorter - and many of them do have plans to do so.
How will the decentralization of sequencers work? There are several methods. On the one hand, we could create a Proof-of-Stake-like system where sequencers must stake tokens to have a chance to come up with the next batch. Or we could do a Delegated-Proof-of-Stake, where a sorter is elected and not elected if it doesn't do well. All in all, it remains to be seen how decentralized the sequencer will be!
Side by side comparison
Yeah. Hopefully you have a better understanding of rollups — and why Ethereum is betting on it (and sharding!) as a scalability solution. Of course, Rollups sits on the shoulders of the giants that came before it — we wouldn’t have it without sidechains, state channels, and Plasma.
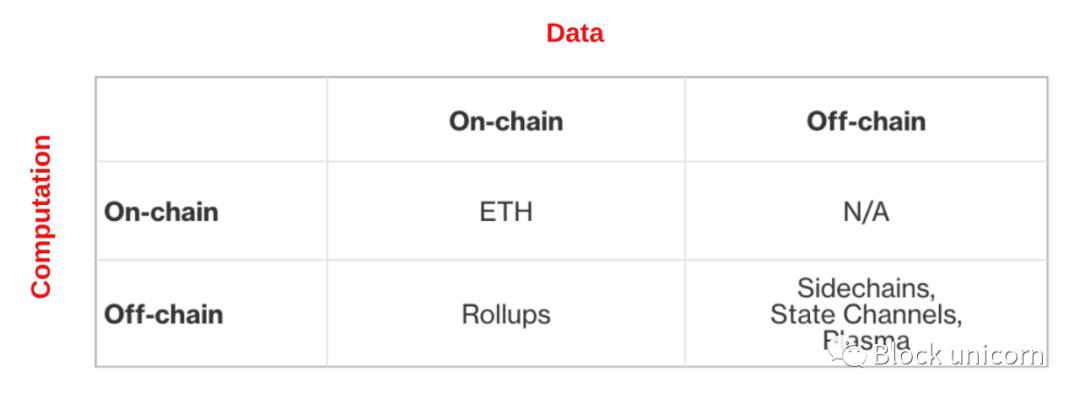
It is also instructive to compare Rollup to other layer 2 solutions using the “trilemma” framework of decentralization, security, and scalability. Except I'll add an extra dimension: versatility. Over the years, we've realized that it's important for layer 2 solutions to be universal so that it can be used to do anything that can be done on the main chain.
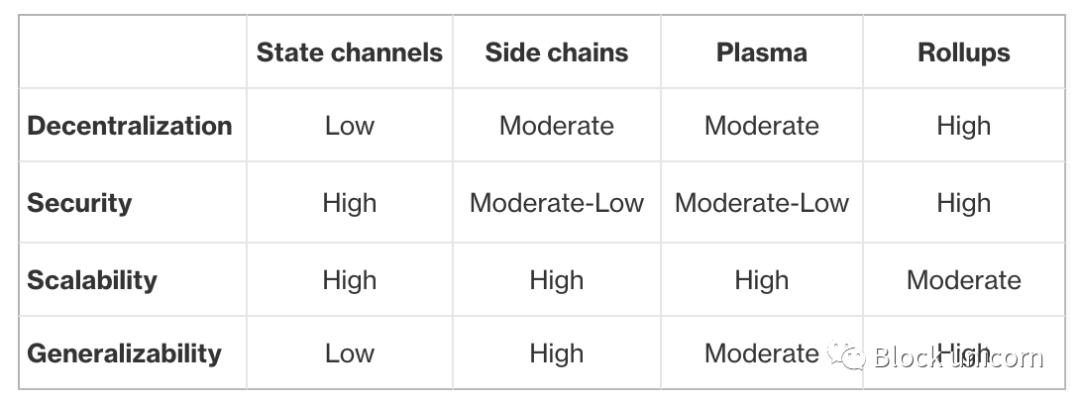
This clearly shows that Rollups gives us modest scalability without sacrificing decentralization, security, and generality.
The trade-off, however, is scalability. Because we still store data on-chain, we are limited in scalability compared to layer 2 scaling solutions that store data off-chain. Also, in the short term, rollups rely on a centralized sorter, which reduces security. But this is a short-term problem, and over time, rollups will likely decentralize the orderer, making it a technology superior to Plasma, sidechains, and state channels.
So summarization is the Holy Grail? I'll let you decide.
PS.. for the sake of brevity, I left out a lot of interesting details about how rollup works. But I also left out a new layer 2 scaling scheme called "Validium". Validium is similar to Plasma in that we move data and computation off-chain. The key difference is that Validium does not rely on fraud proofs to validate transactions. Instead, operators need to make new state commitments using zero-knowledge proofs, which make it impossible for operators to advance invalid state transitions. It also eliminates the need for "mass exit" plans, or long-term exit delays in agreements. But we still get the infinite scalability of Plasma chains because we don't store transaction data on-chain. Anyway, worth mentioning and I encourage you to read it!
Conclusion
This article is much longer than I expected, if you still If you're reading, then you're my type. Although rather lengthy, this is really the minimum you need to know to have a basic understanding of aggregation. After all, rollups are only half of Ethereum's scalability solution. The other half is sharding, if you're interested in building Web 3.0 applications, sign up for our next DappCamp cohort where you'll learn how to build and deploy secure smart contracts on Ethereum.
Original link
a>
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia





