 Forum
Forum OPRR
OPRR Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Data
Data

What is a real Rollup
 Summarized by AI
Summarized by AI
Original title: You're Not a Real Rollup :)
Original article by Jon Charbonneau
ETH Chinese
Kelvin thinks ZK-rollup is fake, but I don't think any "Rollup" is real, at least not yet. So, how do we make them a true rollup?

Current rollups are basically trusted and permissioned:
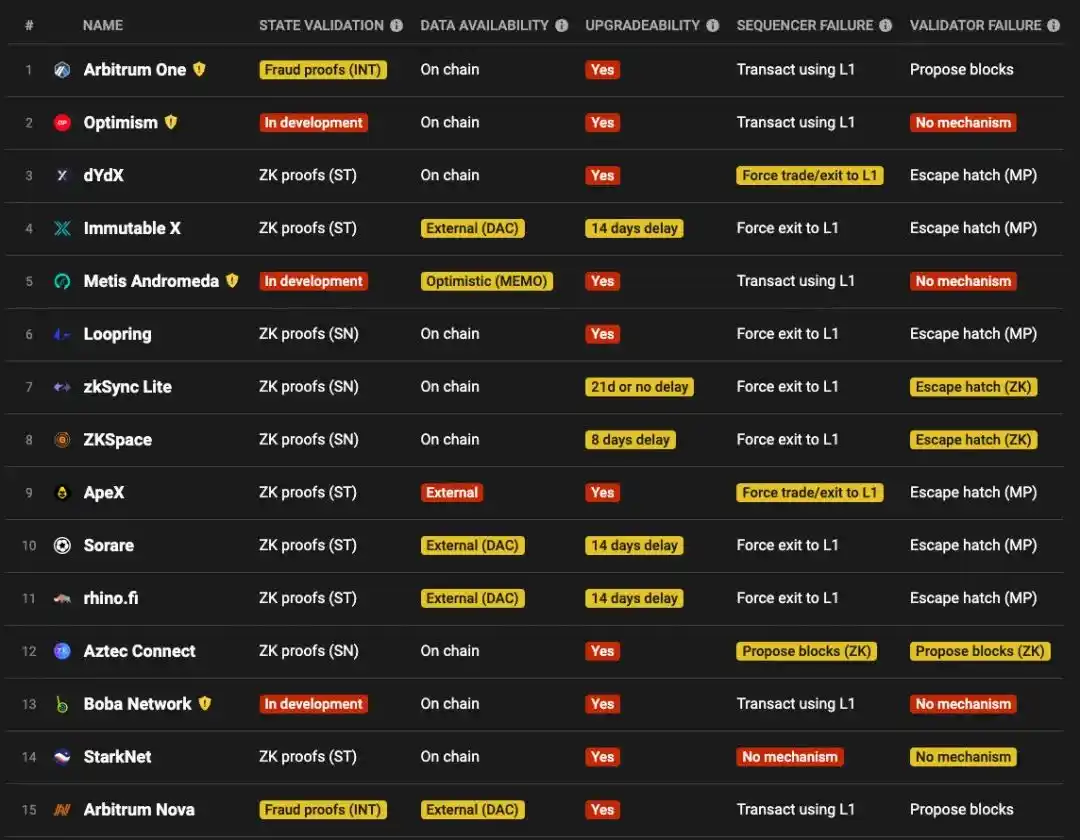
Source: L2 Beat
In this article, I will give an overview of the following:
Enforce a transaction packaging mechanism Even if a rollup operator reviews users, users should be able to force packaging of their transactions to resist censorship.
L2 sequencer decentralization and (optional) local consensus -- Unitary sequencer, PoA, PoS leader election, PoS consensus, MEV auction, base layer based rollup, PoE, etc.
Shared Sequencer and Cross-chain atomicity -- This is something really interesting and completely new.
Mevs capture designs I'll briefly cover some of the changes to FCFS (first come, first served). For encrypted trading pools, you can refer to my recent post.
Many other requirements for improving rollup security are outside the scope of this article (such as reducing the authority of upgrade keys, implementing robust and permissive proofs, and so on).
Rollup works
Smart Contract Rollup (SCR)
First, a quick review of how SCR works, which is the rollup we're currently seeing on Ethereum. At a high level, an SCR basically consists of:
1. A set of ordered input arrays (on L1, so the transaction data must be published at the DA layer).
2. (rollup node software) code that runs on them.
3. Deterministic output (rollup blockchain) generated by running functions on these inputs.
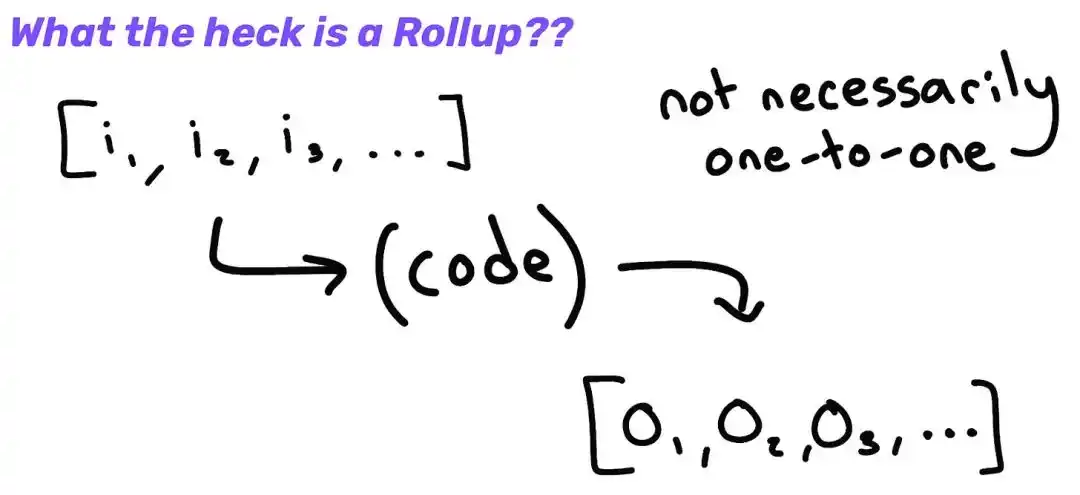
cr: How Rollups *actually* work - Kelvin Fichter
More specifically, a traditional sequester generates a commitment to a rollup block by publishing the status root of the rollup block and the calldata (eventually in the form of a data blob) to its smart contract in L1. New blocks continually extend the rollup to the block header. The on-chain contract runs a rollup light client that stores the hash of its block header. Upon receipt of proof of validity, or after a window for proof of fraud, the smart contract finalizes the settlement. If an unfinalised ORU block is invalid, it (and all subsequent blocks) will be rolled back as a result of fraudulent proof-of-submission, and will end up as an orphan block. Proof to help protect Bridges:


The submission of the transaction batch should require the application of some type of margin/deposit rule to discourage the occurrence of malicious acts. For example, when a fraudulent batch is submitted (i.e. invalid status root), the deposit is destroyed and divided among the fraudulent challengers in some percentage.
SCR has "Consensus on Consolidation" - A consensus protocol that can be verified on the chain. The Rollup protocol can run entirely in L1 smart contracts. It does not affect the arbitrary consensus rules of the main chain, nor does it need to be supported by those rules.
Decentralized consensus protocols usually include four main characteristics. (Note that the following is a very simplified version and does not fully list the various types of consensus protocols. Such as leaderless agreements) :
1. Block validity function - State transition function. Block validity is executed down the chain and then validated by a proof of validity or fraud mechanism.
2. Bifurcation selection rules - How to choose between two otherwise valid chains. Rollup is designed to be structurally fork-free, so a complex fork-selection rule is not strictly required.
3. Leader election algorithm - Elect a leader who can extend the chain by adding new blocks.
4. Anti-witch mechanism - PoW, PoS, etc
Assuming that 1 and 2 have already been implemented, then the minimum requirement for decentralizing a sequencer is some form of anti-witch attack + leader election. Fuel Labs has been a proponent of this camp, arguing that PoS:
Should not be used for the full consensus protocol in rollup (i.e. the rollup verifier/orderer will vote on the block)
Should only be used for leader elections in rollup
Of course, there are other arguments that well refute Fuel Labs' argument that there needs to be an L2 local consensus. More on this later.
Sovereign Rollup (SR)
SR still publishes trade data to L1 for DA and consensus, but SR handles the "settlement" client in rollup (James Prestwich says it's stupid to call a "settlement layer", I'm already stupid, so it doesn't matter). The DA layer tells you that data exists, but it doesn't define what the canonical chain is for rollup:
SCR - rollup The specification chain is determined by the L1 smart contract
SR - There is no L1 smart contract to determine the rollup specification chain. The Rollup main chain can be determined by the rollup node itself (check L1 DA and then verify fork selection rules locally).
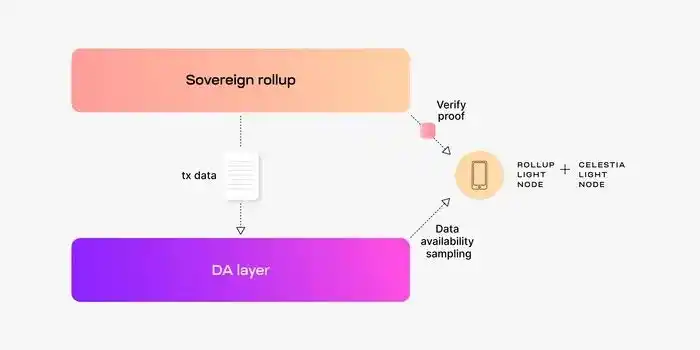
Source : Celestia
Related: There is a strong rebuttal to the interesting idea that there is no global norm chain (only the bridging that determines which one is a norm chain). And other related long extras that illustrate rollup's tradeoff between sovereignty and (automatic) composability. I encourage you to take a look at these views, as well as this recent long tweet about Bitcoin Sovereign rollup.
In any case, the "canonical chain" framework discussed above is easy to understand and is not the focus of this article, so I'll stick with the term "canonical chain" anyway. For more background on rollup's general architecture, see here.
Decentralized sequencer
User-initiated mandatory transaction packaging
Smart contract Rollup
As mentioned above, the sequencer is typically responsible for batch processing transactions and publishing them to the L1 smart contract. However, users can also insert some transactions directly into the contract themselves:
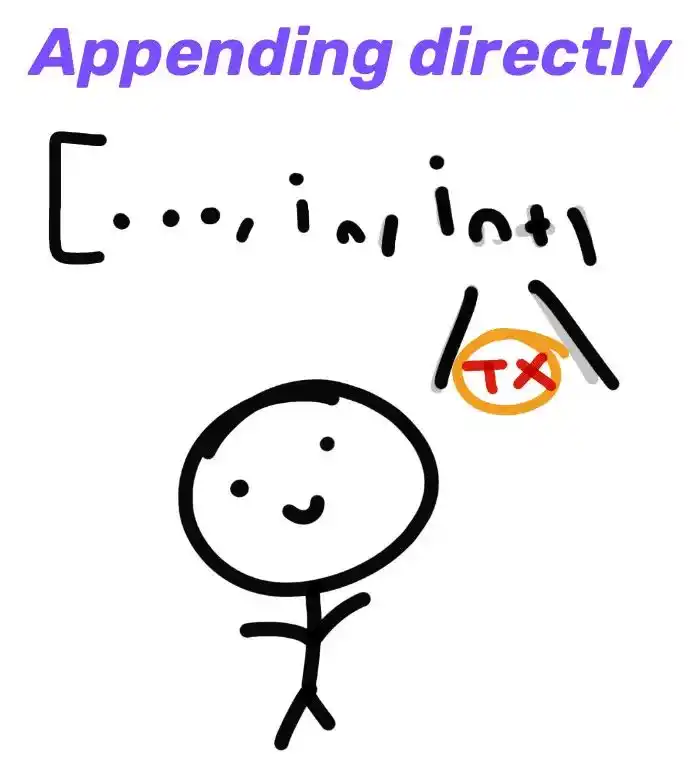
Of course, this is inefficient and expensive, so the sequencer will take care of the batch transactions and commit the batches together in a regular process. This will amortize fixed costs across many transactions, resulting in better compression:

The sequencer promises to eventually publish these transactions on L1, and we can compute the output to get softer pre-confirmation:
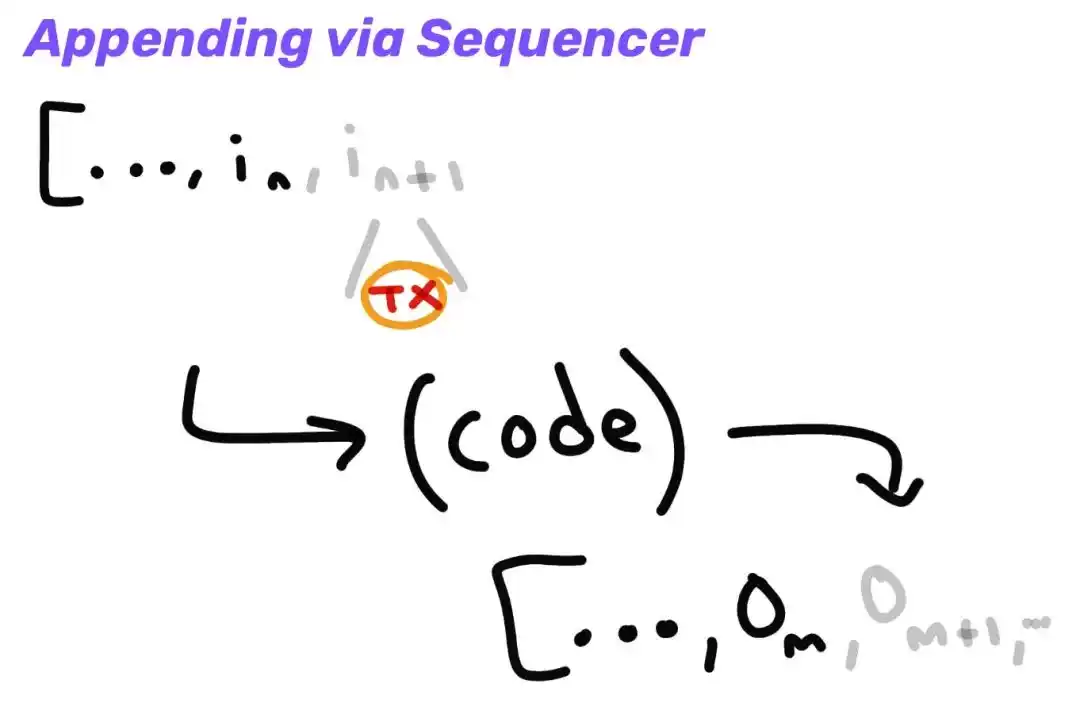
When the sequencer publishes these transactions to L1, the output is finalized:
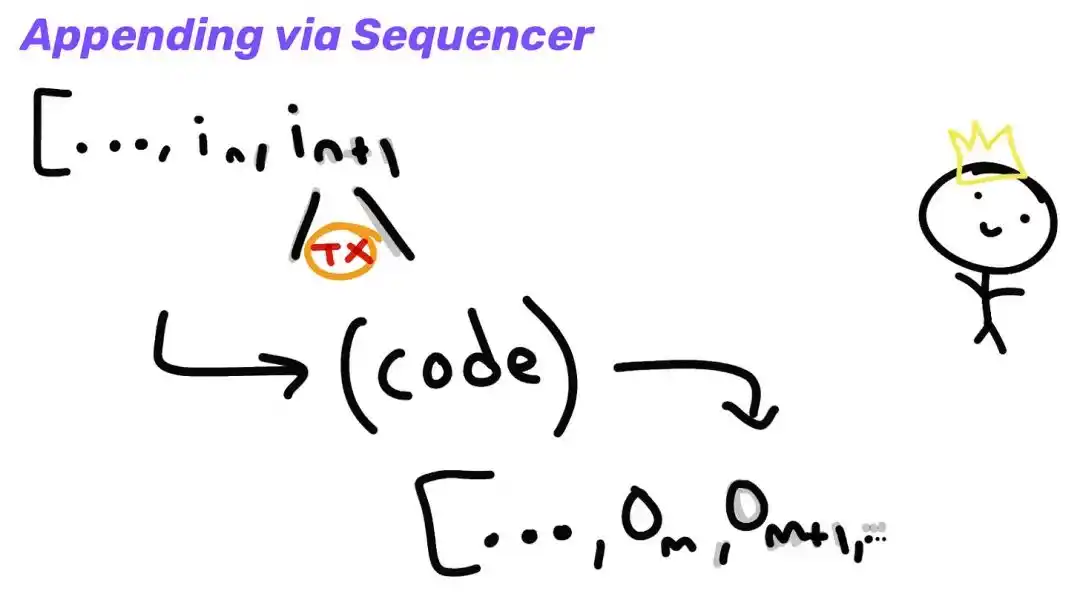
Typically, users will only be required to submit transactions themselves when bridging assets from L1 to L2. This is added as an input to the L1 contract, which tells L2 that it can mint funds backed by the corresponding L1 lock-in asset.
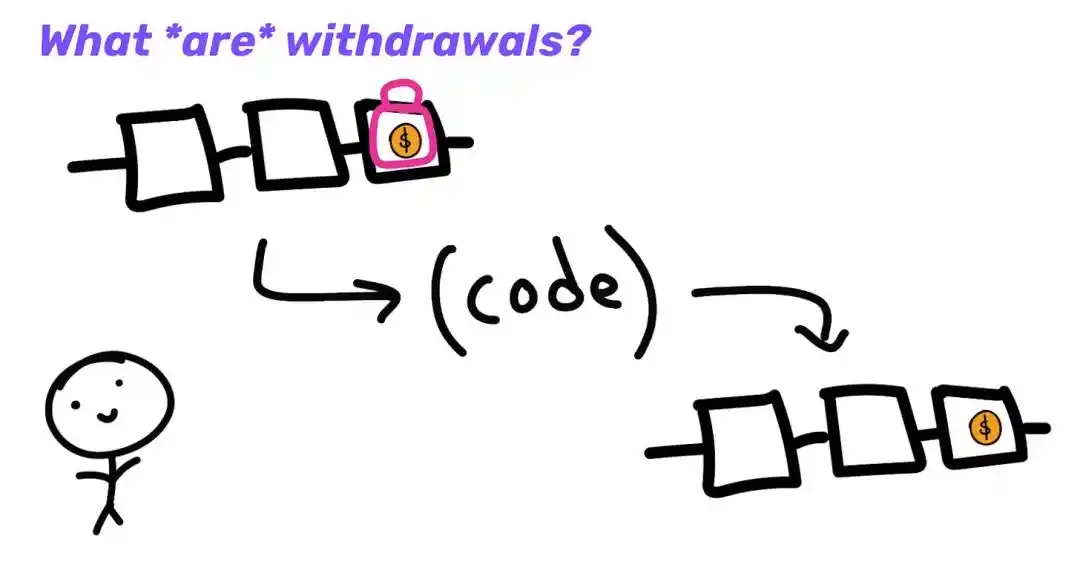
If I want to withdraw my money back to L1, I can destroy it on L2 and tell L1 to give me my money back. L1 didn't know what was going on at L2 (L1 didn't execute the transactions), so needed to submit a certificate along with the request to unlock my funds at L1.
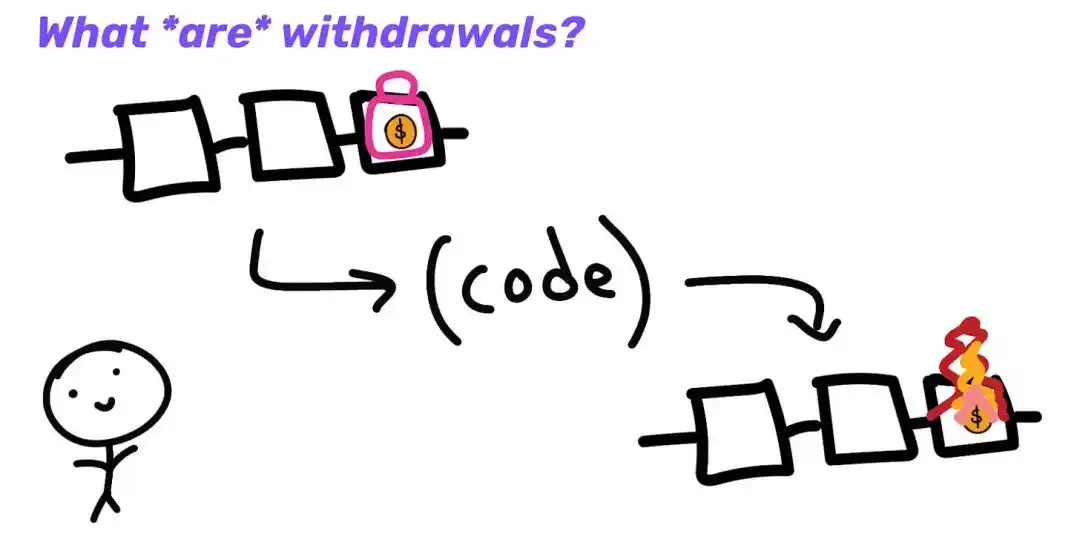
Since I'm from L2, the sequencer can initiate this withdrawal request and submit it to L1. However, to do so requires trusting CR (censorship resistance), which means you no longer have the same security guarantees as L1. Maybe these sequencers don't like you, or maybe the sequencer is down, so you're stuck on L2 forever.
Rollup can increase its CR locally through a variety of measures. This could include L2 consensus sets with high-value pledges, variations on some transaction packaging lists, adding threshold encryption, and so on to minimize the possibility of L2 user review. That's all great, but ideally we'd like L2 users to have the same anti-censorship guarantees as L1.
If users are being vetted, they need some way to force an exit from rollup or force their transactions to be packaged into L2. This is why L2 users should retain the ability to do things such as force their L2 transactions directly into the L1 contract themselves. For example, the user under review might be able to submit a batch of a single operation directly to L1.
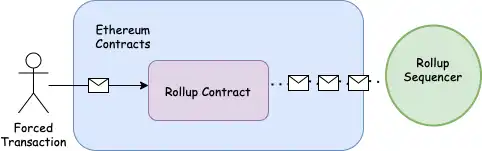
Source : Starknet Escape Hatch Study
However, this is not ideal if the only option for L2 users is to force transactions directly into L1. This may not be feasible for many low value users, especially as L1 becomes more and more expensive to interact with. More advanced designs may be able to bypass this restriction and force atomic transactions between rollups. Kalman Lajk Working on a fascinating design, highly recommended reading. It wants to enable cross-rollup mandatory transaction packaging in systems with shared proofs and shared DA layers.
Sovereign Rollup
Forced packaging works differently in SRS because, as mentioned earlier, they implement different fork selection rules than SCRS (Sovereign Labs wrote a post about this).
In SCR, the L1 smart contract implements rollup's fork selection rules. In addition to verifying the ZK proof, it checks that the proof builds on the previous proof (and not other proof forks), and that it handles all relevant forced packaging transactions sent on L1.
SR can publish its ZK proofs to the L1 DA layer, exposing them to all in the form of calldata/blobs (even if L1 doesn't validate them). Then, simply add a rule that the new proof is valid only if it builds on the previous valid proof. This rule can be enforced on the client side, but it then requires the user to scan the history of the chain up to the creation block or a checkpoint.
Alternatively, you can associate the calldata with the L1 block header and add a statement that says "I have scanned the proof of the DA layer (starting with block X and ending with block Y) and this proof is built on the latest valid proof". This directly proves the fork selection rule in the proof without having to enforce it on the client side.
Since the proof has been scanned, you can also prove that any forced packaging transactions have been scanned. Anyone can publish a mandatory package transaction directly to the L1 DA layer if they wish.
The level at which a deal is struck. ZK is used for quick finalizing
On-chain proof verification on Ethereum is usually very expensive, so current ZKRS (like StarkEx) tend to release STARK to Ethereum only every few hours. The growth of proofs tends to be very slow relative to the number of transactions, so generating a batch of transactions in this way can be an effective cost saver. However, this length of time is not ideal.
If a rollup simply publishes state differences on the chain (rather than complete transaction data), then even full nodes cannot ensure this final certainty without proof. If the complete transaction data from rollup is published on the chain, then at least any full node can finalize the transaction with L1.
Typically, light nodes rely only on a centralized sequencer for soft validation. However, ZKR can quickly generate and distribute ZK proofs at the p2p layer for all light clients to view in real time and provide them with final certainty at L1 speeds. Later, these proofs can be recursively batched and published to L1.
That's it. What Sovereign Labs plans to do, there are other similar schemes, such as Scroll plans to publish intermediate ZK proofs on the chain (but not validate them), so light clients can sync fairly quickly. Using these two structures, rollup can start hammering blocks at L1 rather than waiting for the batch to be sent up the chain to save money. Note, however, that in both cases the "hard nail time" is simply reduced to the absolute minimum (L1 velocity).
Different sequencer designs will never be finalized faster than L1 block time. The best that different sequencer designs can do is to provide prevalidation faster than the L1 block time, with different designs providing different levels of certainty (for example, you might trust L2 prevalidation with a decentralized consensus set with a high value pledge rather than a single, truth-requiring sequencer prevalidation).
Patrick McCorry Recently, too. rollup's hierarchy of transaction finality is well outlined. By now you probably understand the basic concepts:
There are different levels of transaction "final certainty" depending on who is providing the commitment (and what the rollup structure is)
Different participants will have different levels of knowledge of "truth" at a given time (e.g. L2 light client, full Node, and L1 smart contract will know the same "truth" at different times)
Single sequencer
Currently, most rollUps have a license-required sequencer to submit the transaction batch. This is highly efficient, but has low real-time activity and resistance to censorship. This may be acceptable for many use cases if appropriate safeguards are in place:
CR - As described above, the mechanism by which users force package transactions.
Activity - If some major sequencers go down, some hot backup options are available (backups like ZKR prover and ORU fraud prover should be unlicensed). If the backup sequencer goes down, anyone can take over.
For example, alternate sequencers can be selected by rollup's governance. With this setup, users gain security, resistance to censorship, and activity. Even in the long run, a single active sequencer may be a viable option.
Base may well be the start of a trend. Companies can now manage and optimize their products, just like they hyped up the enterprise blockchain, but now it can actually become a permissionless, secure and interoperable chain.
Base intends to eventually decentralize their sequencer set, but the point is that they do not strictly "need" decentralization, whereas other schemes do not (or only need decentralization to a very limited extent, such as a small-scale sequencer set). To be clear, this requires rollup to implement the necessary steps to ensure that rollup is secure and maintained against censorship (remove arbitrary instant upgrades, implement robust proofs, force transaction packaging, MEV auctions, etc.). The current rollup is not secure.
This would be a huge improvement over a centralized/hosted product, not a major replacement for a decentralized product. Rollup just expands the design space. This is in large part why sequencer decentralization is not a top priority for most rollup teams -- other items are far more important to ensuring user security, censorship resistance, and reducing trust in rollup operators.
However, this is still not ideal if the user/other party needs to step in to maintain activity and "real-time censorship resistance" (as opposed to the "ultimate censorship resistance" obtained through a forced packaging transaction through L1). Low value users can be costly or impractical to step in with a forced package transaction. rolllup with a high preference for real-time resistance to review and maximum assurance of activity will seek decentralization. There may also be regulatory considerations when operating a single license sequencer.
Certificate of Authority (PoA)
One immediate improvement to the uniformed sequencer is to allow the implementation of a small number of sequencers distributed in different geographic locations (perhaps by other reputable companies). Sequencers can simply be rotated equally by rotation. Making them post a deposit will help to encourage honest behaviour.
This general concept should be familiar to everyone - multiple sign-on bridge is often some trusted companies, or similar services. Arbitrum's AnyTrust DA The Committee of But importantly, the sequencer has much less power here (the user does not rely on the rollup sequencer for security, unlike the multi-sign bridge operator who can withdraw locked funds). Overall, this scheme has better censorship resistance and activity than a single sequencer, but it is still not perfect.
Sequencer Auction a.k.a. MEV Auction (MEVA)
Instead of assigning rights to sequencers based on pledge shares, rollup can also run directly via smart contracts. MEV Auction (MEVA). Anyone can bid for ranking rights, and auction contracts award ranking rights to the highest bidder. This can be done on a per-block basis or over a period of time (for example, bidding for the next day's sorting rights). The winning orderer should still post a deposit so that they can be penalized in the event of their problematic/malicious behavior.
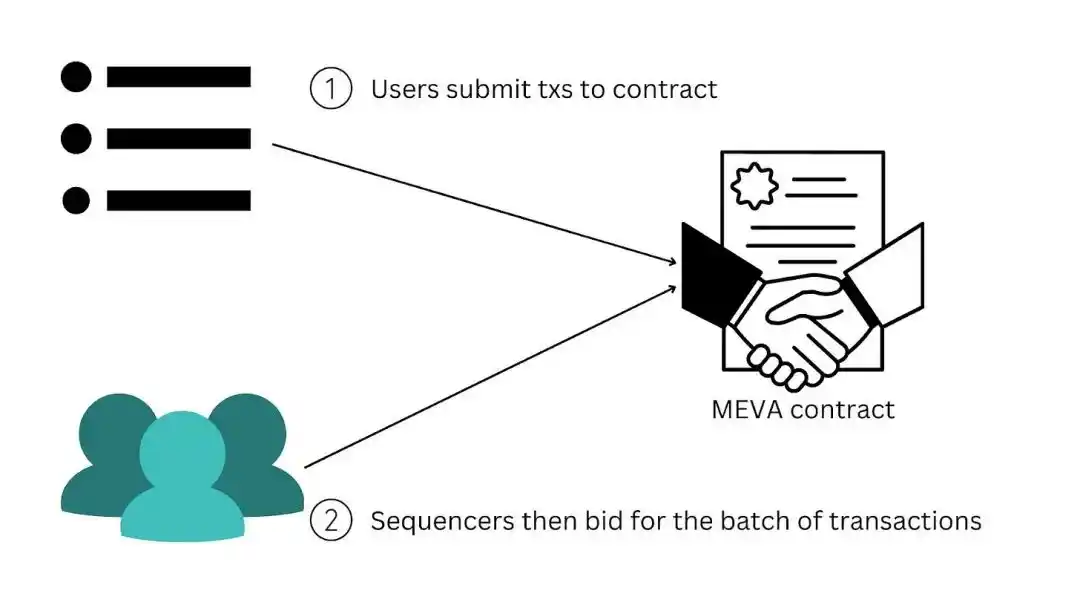
Source : Decentralization of ZK Rollups
In practice, if the auction is not directly embedded in the protocol, it will naturally result in MEVA outside the protocol. If sorting rights were determined based on pledge weights, some form of MEV-Boost/ PBs-type auction system would emerge, similar to what we see today on L1 Ethereum. In this case, the fee /MEV may flow to the pledgee. If the auction is included in the agreement, then the fee /MEV may go into some form of rollup DAO Treasury (although in both cases it can also be allocated, destroyed, etc.).
No licensing PoS required for leader election
Anyone can join as a sequencer without permission, but only if they pledge (possibly L2's original token). The pledge mechanism can be established at the base layer through smart contracts or directly in the rollup. Rollup can use this PoS + some form of on-chain randomness to implement a leader selection mechanism (as some L1s do).
Probability that anyone gets block sorting rights = ta's pledge as a percentage of total pledge. Penalties can be imposed on error/malicious sequencers through lost rewards, sabotage penalties, and forfeitures.
Note that this does not require a sequencer consensus for the reasons above. Rollup uses L1 as consensus, so no local consensus is required. Pledge weights play a dominant role in the rotation mechanism, determining which sequencers can propose blocks, but they do not need to vote on blocks proposed by other sequencers.
This grants sorting rights to epochs of any length. An actor might have the right to sort 100 consecutive rollup blocks, or 1000, and so on. Longer cycles may be more efficient and require only one sequencer at a given time. However, empowering an extended monopoly has other externalities as well. Alternatively, the leader can alternate each block as normal L1 does.
Dymension
Dymension It is such a project. Dymension Hub will be a typical L1 in Cosmos using honest most PoS mechanisms. Its L2 (" RollApp ") will use it for settlement and consensus, while relying on Celestia as the data availability store (so these L2s are actually "optimistic chain" rather than "rollup").
According to their Litepaper, decentralized RollApp sorting will need to pledge DYM (Dymension's native asset) in the Dymension Hub. The leader election is determined by the corresponding number of DYM pledges. The sequencers will receive revenue (fees and other MEVs) from their respective rollups and then pay the associated base costs to Dymension Hub and Celestia.
Because of this mechanism, almost all of the value captured in this stack accumulates directly into the DYM token. And if they use their native tokens for a sort rollup (as StarkNet intends to do with STRK, described below) they accumulate value into their own tokens. Dymension Hub is set up like Ethereum rollup can only use ETH for sequencer elections.
In my opinion, this greatly reduces the incentive to deploy L2 on such a clearing layer. Most L2 teams naturally want their own tokens to accumulate meaningful value (and not just be used as fee tokens, as is possible here). They are running a business, after all.
Election of leaders No license PoS required for L2 consensus
If desired, L2 pledges can also be used for sequencer elections and L2 local consensus before L1 is finalized.
PoS Sequencer Leader Election As mentioned above, some form of leadership election is necessary.
PoS Consensus -- Encourage L2 validators to reach a provisional L2 consensus before the transaction is finalized by L1 to provide stronger pre-confirmation. As mentioned above, this is not a strict requirement, but it is an attractive option.
In addition, STRK can be used in some form to:
PoS Consensus of DA - & have spent Use to motivate alternative chains of DA (alt-DA, such as volition), which require a separate consensus.
Proof - & have spent The excitation prover generates STARK.
The transaction process is as follows:
1. Sequence - The sequencer sorts transactions and proposes a block
2. L2 consensus - The StarkNet Consensus protocol signs the proposed blocks
3. Proof generation - The prover generates proofs for the agreed blocks
4. L1 status update -- Submit proof to L1 to update status
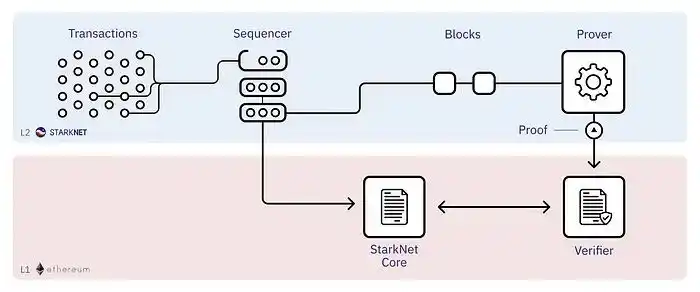
For more details on StarkNet's plans, see this series.
Is L2 consensus needed, or just L1 consensus?
As we have seen, L2 may or may not implement its own local consensus (that is, L2 verifiers sign their blocks before sending them to L1 for a final consensus). For example, L1 smart contracts can react differently based on their own rules:
PoS using leader elections and local consensus; -- "I only accept blocks that have been signed by L2 consensus."
Use the PoS for leader election; - "Currently, only selected sequencers can submit blocks."
If there is no local consensus for rollup, here is what needs to be done:
Makes the rollup block proposal process permissionless.
Create some criteria to select the best block for a given block height
Have nodes or settlement contracts enforce forking selection rules
Inherited consensus and final certainty of L1
Note that in either case, the value of L2 can be accumulated into the rollup token. Even if the L2 token is only used for some form of leader election (as opposed to consensus voting), the value generated by ranking rights will still accumulate into the L2 token.
L2 Disadvantages of consensus (leader election only)
Now let's discuss the trade-off between having/not having local consensus before L1 is finalized.
One argument made by the Fuel Labs team is that L2 local consensus reduces resistance to censorship. "This allows most verifiers to review new blocks, which means user funds may be frozen. Rollup does not need PoS to guard it, as rollup is protected by Ethereum." This is a little bit of a gray area. As mentioned earlier, rollup can still provide anti-censorship solutions even when the sequencer reviews transactions (for example, directly force transaction packaging into L1, or more complex designs such as Kalman Lajk The one being studied).
Another way to put it is that complete consensus is simply "inefficient". For example:
With a single ordered leader running everything in a single box at a time,
There's a single ordering leader running everything in a single box at a time, and then all the other nodes have to vote and agree on the proposal,
The former is much simpler than the latter.
Of course, this varies greatly depending on the particular sequencer design and consensus mechanism chosen.
Also, note that some concerns have been raised about the use of PoS in sequencer decentralization, as here and here. The intricate relationship between L1 and L2 can make dealing with certain types of attacks more challenging.
Added benefits of L2 consensus (plus leader election)
For sequencers, the biggest goal is probably to give users faster soft validation before the full security provided by L1. Take a look. StarkNet's mechanism requires:
"Robust and fast L2 final certainty is StarkNet's goal. As the status of StarkNet will only be finalised after the transaction batch is certified by L1 (which could take several hours). Therefore, by the time the next batch is certified, the L2 decentralisation agreement should make a meaningful commitment to the planned sequence of transaction execution."
Adding some form of consensus (backed by economic security from many orderers) helps to provide stronger assurance in the interim. (The rollup block pre-validation is fine) :
"The Starknet consensus must have a strong sense of responsibility that violations of safety and activity can be punished by forfeiting any portion of the participants, including most pledges in bad faith."
Rollup also has the flexibility to experiment with tradeoff points between the spectrum of different consensus mechanisms, as they can always ultimately come back to the security and dynamic availability of Ethereum L1.
L1 is responsible for the sort Rollup
All of the above methods give the sequencer the privilege to create a rollup block in some form. For example, PoS is added without permission, but the L2 sequencer selected for a given slot is the only party that can commit a block at that time. In addition, there are related proposals to not grant privileges to any L2 sequencer. These designs rely on L1 itself to sort transactions.
Total anarchy
Vitalik came up with this "total anarchy" idea back in 2021. Allows anyone to submit a trading batch at any time. The first deal to extend rollup is accepted. It meets the two minimum requirements above for discussing how to decentralize sequencers:
Anti-witch -- Witch resistance provided by L1 (i.e. transaction cost and block size /gas cap).
Leadership Election -- Leadership elections are implicit and delayed.
This is enough because L1 already provides security. If L2 blocks have been published to L1, they will only become isolated if they are invalid or built on invalid blocks (which will be rolled back). If they are valid and published to L1, they have the same security guarantees as L1 itself.
One big problem with this approach, Vitalik points out, is that it would be very inefficient. Multiple participants may submit the batch in parallel, and only one will be successfully packaged. This wastes a lot of effort in generating proofs, or costs a lot of unnecessary gas to release the transaction batch. Trying to find out if your deal will be packaged quickly is cumbersome and inefficient.
Rollup (Based Rollups)
Now, however, it is possible to make this anarchic design feasible through PBS. It allows for more rigorous sorting, with at most one rollup block per L1 block, thus not wasting gas. (Although there may be wasteful calculations). The L1 builder can package only the highest value rollup block and bid to build that block based on the searcher's input, similar to any L1 block. To avoid computational waste, it is also reasonable to make the ZK proof process licensing by default. (There is a mechanism to allow rollback without permission).
That's it. Justin Drake Recently proposed "Rollup Based on Foundation Chain" The core concept of He uses the term to refer to rollups where L1 (the "base" layer) dominates sorting. The L1 proposer just needs to make sure to include the rollup block in their own L1 block (presumably through the builder). This is a simple setup that provides immediate L1 activity and decentralization. They can avoid some thorny issues, such as resolving the issue of forced packaging transactions while the L2 sequencer is under review. In addition, some gas overhead can be reduced because no sequencer signature validation is required.
An interesting question is where these L2 transactions are processed. The L2 client needs to send these transactions somewhere for the L1 searcher/builder to receive them and create blocks and data blobs against them. They may be sent to:
L1 trading pool They can be sent along with some special metadata to "informed" searchers/builders to interpret them. However, this can significantly increase the load on the L1 trade pool
A new p2p trading pool for each L2 Some solutions along these lines seem more compelling. In addition to their usual channels, the searcher/builder will begin to examine and interpret the transactions of these new trade pools.
One obvious disadvantage is that the underlying chain-based Rollup limits the sequencer's flexibility. For example:
MEV remission Rollup can creatively use variants of FCFS, crypto trading pools, and more.
Pre-confirmation - L2 users like quick transaction "confirmations". At most, the underlying chain-based Rollup will go back to the L1 block time (12 seconds), or wait longer to publish the full transaction batch.
Interestingly, this is what the early rollup team was building
https://twitter.com/DZack23/status/1635503593070657536?s=20
restaking might help, argues Justin.
https://twitter.com/jon_charb/status/1635898303106756609?s=20
These are all things. EigenLayer At least mentioned in their white paper. It is not clear that this is a practical solution. In order to effectively ameliorate these shortcomings through repledge, it may be hoped that all the pledgees choose to run it. So the idea seems more logical to implement this way: let the subset of pledgers who want to do so choose to enter a separate shared sorting layer (more on that later).
Proof of Efficiency (PoE)
Last year, Polygon Hermez proposed a study called PoE The proposal. This is another L1 ordering variant that is specific to ZKR. The sequencer here is a fully open role, and anyone can submit a transaction batch (that is, a completely anarchic/infra-chain-based Rollup, so it has the same limitations). The PoE mechanism consists of two steps:
sequencer
The sequencer collects L2 user transactions and creates a transaction batch by sending an L1 transaction that includes data for all selected L2 transactions. The sequencer will submit blocks based on the economic value received, or provide a service-level experience for the user (for example, publishing a transaction batch in each L1 block, even if it makes L2 transactions more expensive because the user wants the transaction to complete faster).
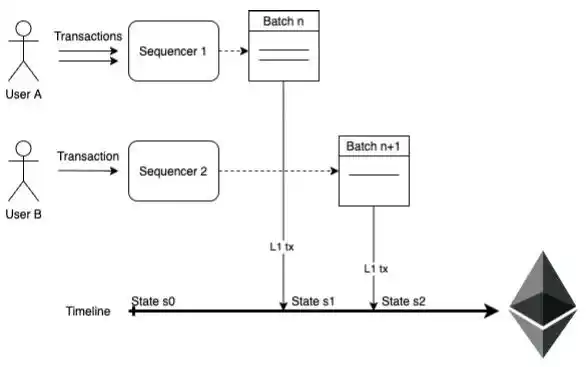
The sequencer will pay L1 gas to release the transaction batch, and the protocol defines additional charges in MATIC that must be deposited. Once published, the winning batch immediately defines a new chain head, allowing any node to deterministically calculate the current state. A proof of validity is then required to seal the light client witness (including the L1 smart contract).
polymerizer
The aggregator here refers to the ZK- prover. Again, this is a permissionless role for which anyone can compete. Very simple:
Sorted batches carrying transaction data are sorted on L1 according to where they appear on L1.
The PoE smart contract accepts the first proof of validity that is updated to the latest valid state, which includes one or more proposed batches that have not yet been verified.
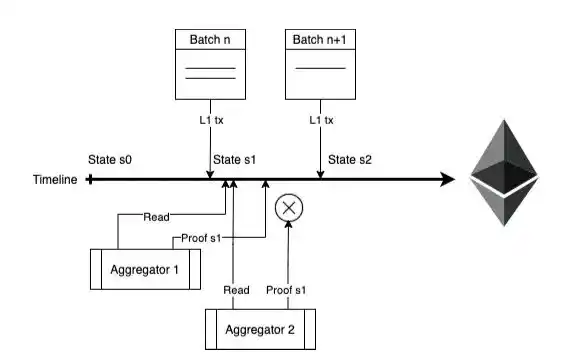
Aggregators are free to run their own cost-benefit analysis to find the appropriate frequency of release proofs. If they win the contest, they get a portion of the fee, but if they wait longer to issue a new proof, their fixed verification costs are amortized over more transactions. If the aggregator publishes a proof late (it does not prove a new state), then the contract will only perform a recovery function. Provers waste computation, but they save most of the gas.
Expenses will be allocated as follows:
The cost of L2 transactions will be processed and allocated by the aggregator that creates the proof of validity.
All transaction costs are sent to the corresponding sequencer for each batch.
The fee deposited by the sequencer for permission to create a single batch is sent to the aggregator, which includes the batch in the proof of validity.
Pure fork selection rule
Rollkit SR has a very similar concept of a "pure fork selection rule", as described here, referring to an arbitrary rollup without a privileged sequencer. Nodes are sorted according to the rules of DA layer, and the fork selection rule of "first come, first served" is applied.
L1 ordering economics
These L1 ordering designs have important implications for economics, because they do. Mevs generated by L2 transactions will now be captured at the L1 block producer level. In the "traditional" L2 ordering model, the MEVs generated by L2 transactions are captured by the L2 sequencer/consensus participant/auction mechanism. It is unclear how much of the MEV could leak into the base layer in this case.
It's hard to say whether this is a good thing or a bad thing:
Benefits - This is a bit like an "L1 economic alliance" (for example, ETH can capture more value).
Disadvantages -- There are concerns about this base-layer excitation. (For example, the centralised risk of bitcoin miners, but it may be too late).
Sorting with L1 might also work, especially if it makes it easier to start a rollup, but it is unlikely that they would give up so many MeVs to L1 that they could capture them themselves. One of the biggest benefits of Rollup is indeed economic - once the DA layer starts to expand, these costs fall and they pay very little to L1. Slower block times and primitive MEV methods are also less than ideal for users.
Excited ZK formation
As a brief aside, note that the competitive market described above in PoE can be centralized around the fastest aggregators. There are basically two economic problems that the market needs to solve:
How do you incentivize the prover to create this proof
How to make submitting proofs permission-free so that it becomes a competitive and robust marketplace (for example, the primary prover goes down without affecting the network)
Let's look at two simple models of the ZK prover market:
Competitive market
At one extreme, you can have an open competition model. In an unlicensed prover market, all provers scramble to create a proof for the rollup sequencer/consensus generated block. The first person to create a proof can receive any reward assigned to the prover. This model is very efficient in finding the best prover.
This looks very similar to proof-of-work mining. However, there is a unique difference here - the proof is deterministic computation. Thus, a prover with a smaller but consistent advantage will almost "always" win. The market could easily become centralized.
In PoW mining, the randomness aspect has better properties -- if I have 1% mining power, I should get 1% bonus.
This competitive proof model is also suboptimal in terms of computational redundancy - many provers will compete with each other and spend resources to create the proof, but only one will win (similar to PoW mining).
Rotation-based mechanisms (e.g., pledge weights)
Alternatively, you can rotate between provers so that each of them has a chance (for example, based on some pledge, or based on reputation). This may be more decentralized, but it may introduce inefficiencies such as proof delays (a "slow" prover will have the opportunity to create a proof, while another prover may already have the ability to create a proof faster and more efficiently). However, it prevents many provers from wasting calculations by racing to create a single proof, after all, only one will be valid in the end.
Furthermore, if the person whose turn it is fails to produce proof (whether maliciously or accidentally), there is a problem. If the rotation is long (for example, the prover whose turn it is can monopolize proof generation for several hours) and the prover goes down, the protocol will be difficult to recover. If the round time is short, other provers can step in and catch up where the primary prover failed to generate proof.
You can also allow anyone to post a certificate, but only the designated certificator will receive the reward within a given period of time. So if these designated provers go down, another prover can publish the proof, but they won't get the reward. This would be selfless, since there is no return on spending resources on computing.
Scroll is exploring more rotation-based approaches to assign the execution trace to a randomly selected "roller" (prover) :
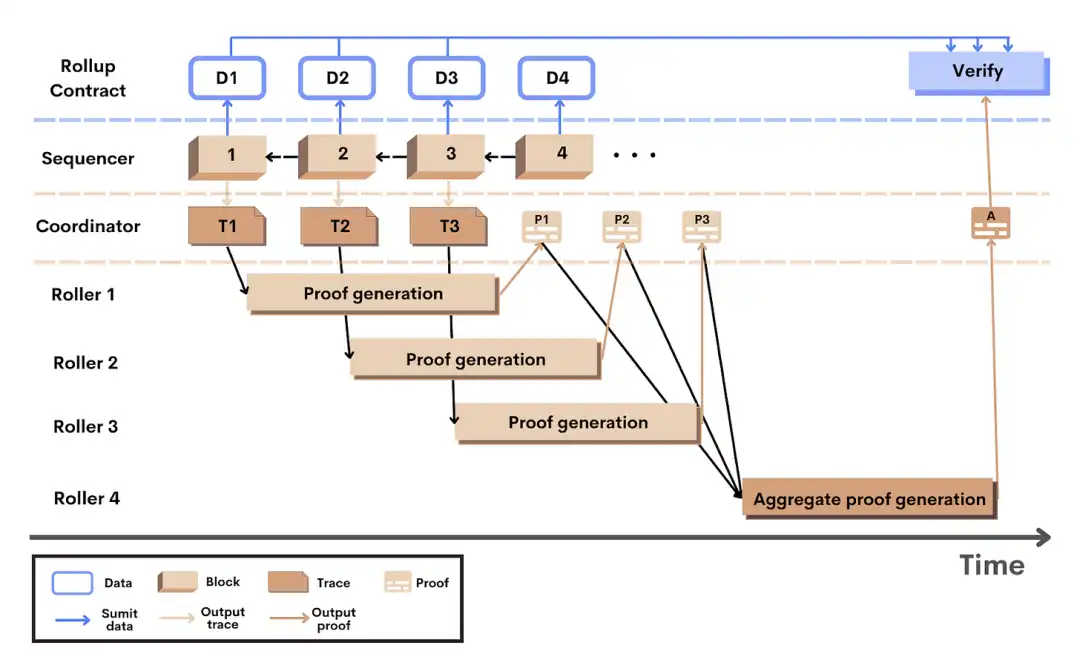
There are also a number of interesting questions about how proof fees should be charged at the user level when ordering. Further discussion of these topics can be found here:
- Scroll nbsp; Ye Zhang In his article "Decentralized zk-Rollup", he discusses the possibility of such a rotating roller network based on pledge + MEV auction for sorting rights without the need for L2 consensus
- The Scroll Architecture Overview provides more details about a possible roller model
- Starknet Decentralization Protocol IV - Proof in the protocol
- Starknet Decentralized protocol VI - The Buffer Problem
Shared sort
Most early solutions assumed that each rollup would need to figure out how to decentralize their sequencer entirely on its own. This is not the case, for example, with the L1 sorting option mentioned above. Many rollups may choose to use a Shared Sequencer (SS). This has some big benefits:
Lie flat -- Stop worrying about how to decentralize your sequencer, it's hard! Embed this option. There is no need to recruit and manage an additional subset of validators. While there are always a lot of "modular" financing pitches, this is a very "modular" approach -- sorting deals into a separate layer. Shared Sequencing is actually a SaaS sequencing as a service company.
Pooling Security and Decentralization-- Having a single sort layer establish strong economic security (stronger prevalidation) and real-time censorship resistance, rather than implementing many small committees for each individual rollup.
Rapid transaction confirmation -- Other unitary rollup sequencers can do the same thing, but note that users can also get super-fast subL1 block time prevalidation in the shared sort case.
Cross-chain atomicity -- Executes transactions on both chain A and chain b (this is complicated, so I'll explore this in more detail below).
Simply using native L1 as a sequencer for many L2 basically has several disadvantages:
Still limited to data and transaction sorting throughput for L1
Loss of ability to provide L2 users with fast transaction confirmation times faster than in L1 block (although with weaker guarantees before final L1 consensus is reached)
The best thing L1 sort can do is remove the computational bottleneck of L1 (for example, if transaction execution is a bottleneck for throughput) and achieve small factor improvements in communication complexity.
So, can we design a dedicated and more efficient shared sorting layer, rather than having L1 do this...
Metro-Astria's shared sequencer
Metro is a proposal for a shared sorting layer. You can refer to Evan Forbes Research articles, Learn more details about the presentation on modularity and the Shared Security Summit Presentation. By Josh Bowen A team of leaders. Astria Is working on implementing Metro's design.
Separate execution from sorting
The current Rollup node actually handles three things:

The key attribute here is "execution and sort separation". In this case, the shared sequencer:
Sort transactions for the various chains that choose to use it as the sort layer
Do not execute (or prove) These transactions generate a result state on them
Sorting is stateless. The shared sequencer node no longer needs to store the complete state for all the different rollups. They remove the execution calculation. The huge bottleneck faced by traditional sequencer no longer exists.
Consensus becomes especially efficient when implementation is taken out of it. This process is only limited to the information broadcast layer (and thus becomes fast). Nodes can be very efficient if all they have to do is generate sorted blocks of transactions and reach a consensus on that block without doing everything. Execution and proof can be the responsibility of the other party after the sequencing consensus has been reached.
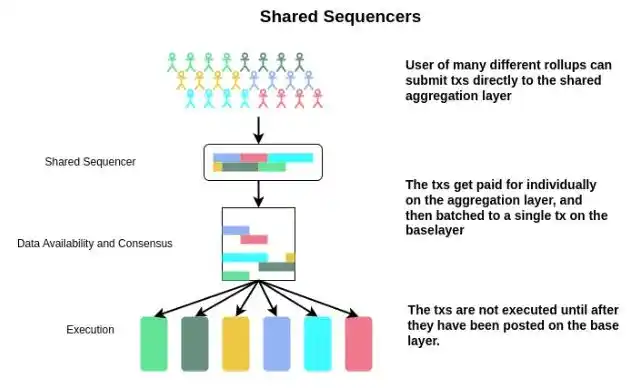
Convergence sequencer security and decentralization
Shared sequencer nodes can remain relatively lightweight and can even be scaled horizontally (sorting different subsets of transactions by selecting a random subset of consensus nodes). As a result, this sorting layer may become more decentralized. The traditional sequencer needs to store the large state of the chain and execute it completely.
In addition, we pool resources across many chains -- no need to split PoS consensus among many rollups. Get them all in one place. Compared to many rollups that implement their own sequester subsets, this approach may result in a more decentralized sequester subset (anti-censorship), on which more forfeitable value is pledged (anti-recombination). This is important because:
Sort -- is the first line of defense to provide rollup users with real-time censorship resistance and activity.
Execution and Proof -- can be done in sorting, without strong decentralization requirements. All we need is an honest party.
Once consensus is reached on transaction sequencing, execution (and proof) can be deferred to a completely different chain:
Soft Consensus and Sequencing - Shared sequencer provides users with fast prevalidation
Confirmed consensus and DA - Transaction data has been finalized at the DA level and is available for all to see
Easy to implement and prove - Anyone can perform and generate proof of the confirmed transaction status
Work done at the executive level does not need to be decentralized because it is not a source of resistance to censorship. A single sequencer is not ideal for anti-censorship, but the point that is not conducive to anti-censorship has nothing to do with the execution process of the sequencer. Their review rights come from their ability to sort and package transactions. At the executive level, shared sequencers already provide sorted transaction inputs, and thus provide censorship resistance. Then the subsequent calculation and comparison of state commitments need not be so decentralized.
Soft execution
The first step to fast soft execution is what users like:
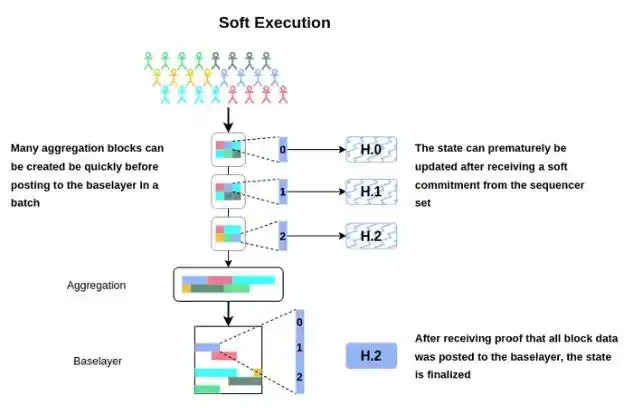
This requires some form of consensus (or a centralized sequencer) to provide a great user experience like this:

If you just rely on the consensus of a base layer like Celestia, you don't do a good job of securing these soft promises about sorting and packaging. If the shared sorting layer has a decentralized committee that pledges a lot of value, it can provide a fairly strong commitment to fast block out (subL1 block time).
Thus, once the shared sequencer creates a block, the user can get a soft acknowledgement. Anyone can download agreed transactions and apply them to the state ahead of time. The strength of this validation depends on the construction of the shared sequencer (decentralization, economic security, bifurcation selection rules, etc.). Once the data is actually released to the base layer, these transactions can be considered finalized. The final calculation of the state root and associated proofs can then be generated and submitted.
Rollup (Lazy Rollups) Rollup (lazy Rollups)
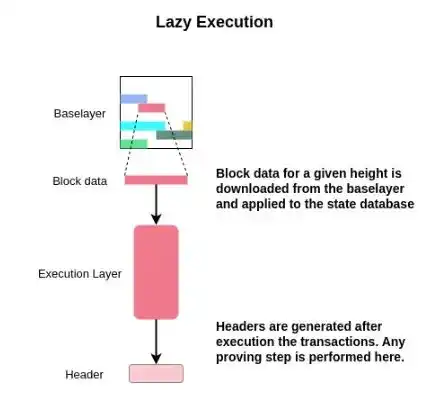
"Lazy Rollup" is very simple. These rollups wait until their transactions are all sorted and published to the DA layer, then they can download those transactions, optionally apply a fork selection rule to select a subset of transactions, perform transaction processing, and apply those transactions to the state. A blockchain head can then be generated and broadcast.
Note that because shared sequencers cannot generate blocks in a way that accesses the full state, they do not have the capability to check for invalid state transitions. Therefore, the state machine using the "lazy rollup" of the shared sequencer must be able to process invalid transactions. The node can simply delete the invalid/rolled back transactions while executing the sorted transactions to calculate the result status. Traditional rollups that implement just-in-time execution have no such limitations.
If rollup requires access state to compress transactions and then package them up the chain, it won't work here. For example, here rollup has a block validity rule where all transactions contained in a block are valid. If a rollup needs to compress transactions but does not require state access, a special shared sequencer can be created specifically for this type of rollup (for example, a rollup like Fuel v2 or a rollup with a private trade pool).
Pay gas
For this shared sequencer to work, there must be some mechanism for users to pay for their transactions to be packaged into L1. The existing signatures and addresses that are already included in most rollup transaction types can simply be used to pay for the gas of the shared sort layer. This would require the shared sequencer to know the minimum state required for different implementations, such as: parsing signatures, nonce, subtracting gases from accounts, and so on. Alternatively, payment can involve some encapsulated transaction on a shared sequencer, where anyone can pay for any data packaged. This is an open design space.
Bifurcation selection rule
Rollup can inherit the fork selection rules of the shared sequencer they use. Then, the full nodes of rollup are actually light clients of the shared sequencer that check some promise to indicate which rollup block is correct for a given block height.
However, the fork selection rule for inheriting shared sequencers is optional -- you can simply ask rollup to process (and not necessarily execute) all transaction data submitted to the base layer. It would effectively inherit the censorship resistance and activity of the base layer, but at the expense of the functionality that many users enjoy with shared sequencers.
MEV
If a rollup wants to inherit the fork selection rules of its shared sequencer and get fast soft execution, the shared sequencer will naturally be in a very centralized position from the MEV perspective. It determines what transaction packaging and sorting rollup will abide by.
However, it is not that rollup must execute the transactions provided by the shared sequencer, or in the order provided. Technically, you can allow your rollup operations node to perform a second round of processing to reorder transactions published by the shared sequencer after execution. However, as mentioned above, you would lose most of the nice features of using a shared sequencer first, so this seems unlikely.
Even in this case, the MEV may still exist in the shared sorting layer, because it has the right to package transactions. If you really wanted to, you could even allow your rollup to exclude certain trades in the second round of processing (e.g., take advantage of some validity conditions to exclude certain trade types), but this would of course become confusing, reduce censorship resistance, and again lose the benefit of a shared sequencer.
Switch shared sequencer
What's hard to fork in a blockchain is any form of valuable shared state. Look at things like ETH vs. ETC or similar ETH vs. ETH POW where the social consensus determines what is "real Ethereum". The "real" state we all agree on has value.
However, a shared sequencer is really just a service provider -- they have no valuable state associated with them. A rollup using a given shared sequencer retains the ability to fork, and only a smaller hard fork is needed to switch to other sorting mechanisms (for example, when the shared sequencer is extracting too much value). This will hopefully keep the shared sequencer competitive.
Network effects could make this even more challenging. If many rollups are starting to use shared sequencers, and they gain large network effects (for example, if they gain meaningful value from the potential cross-chain atomicity of many chains), it may be painful to get out of this network effect unless other rollups are willing to transfer as well.
Espresso Sequencer,ESQ - Security is provided by EigenLayer
You may have seen that. EigenLayer White Paper Decentralized shared sequencer is one of the potential consumers of repledge. This shared sequencer can be protected by the ETH repledge, and it can handle many different L2 transaction ordering.
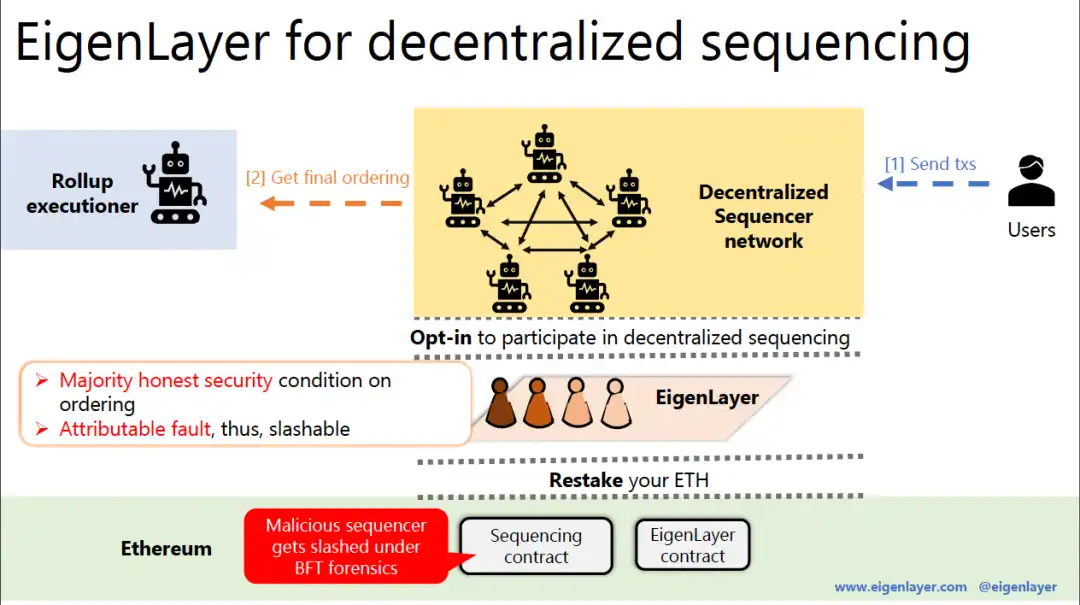
Well, Espresso just publicly announced their plans for a shared sequencer. It can use EigenLayer repledge to provide security for its consensus. For better visualization, here is what the current rollup looks like:
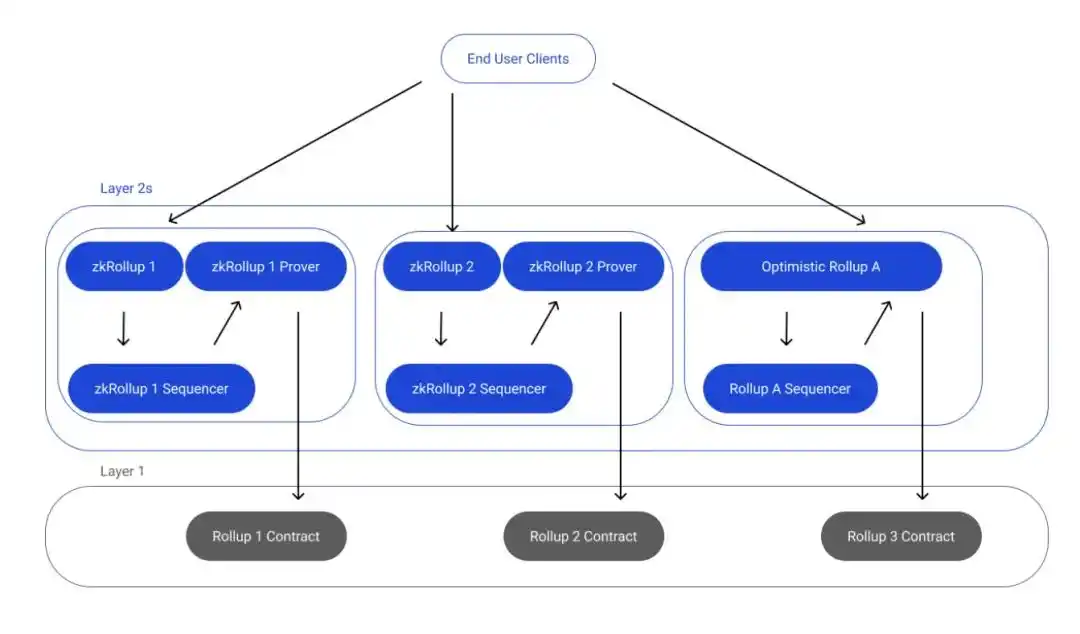
Here is rollup with a shared sequencer like Espresso:
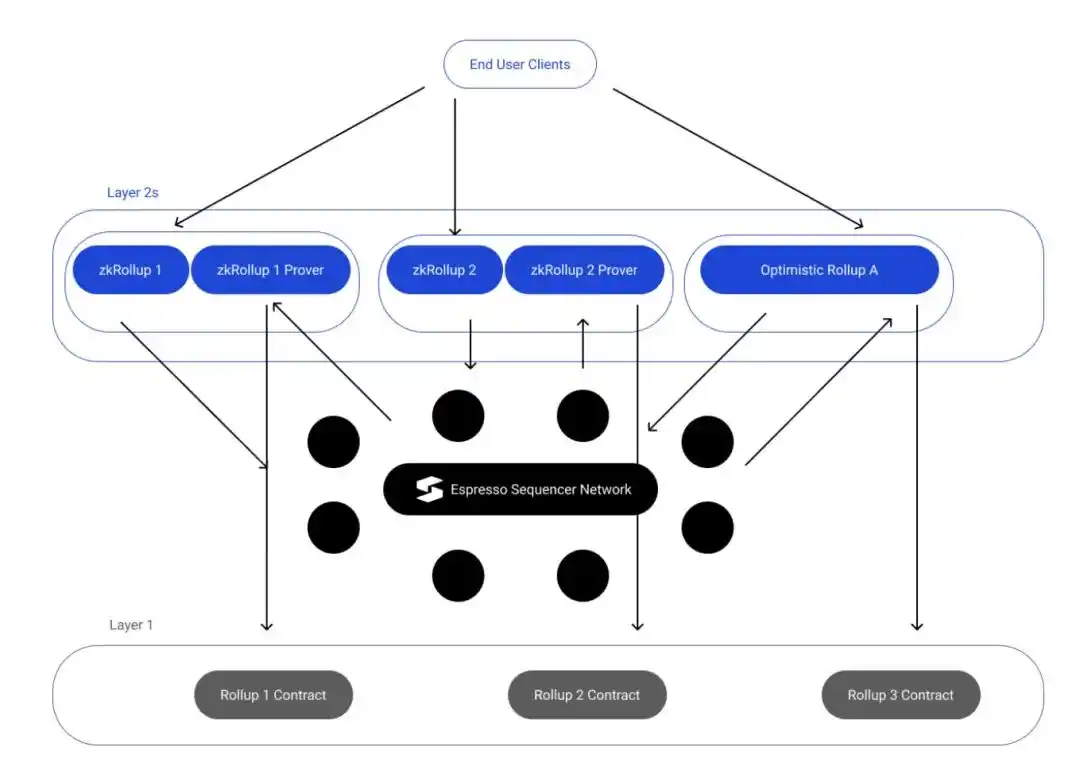
Espresso Sequencer (ESQ) is very similar to the general idea of Metro. It works the same way -- taking trade execution out of the sequencing. In addition, ESQ will also provide data availability for transactions.
HotShot Consensus & Espresso data Availability (DA)
Just a bit of background, Ethereum currently uses Gasper as its consensus mechanism (Casper FFG as the finalizing tool + LMD GHOST as the fork selection rule). Related to this "too long to read" is the ability of Gasper to maintain network activity even under pessimistic conditions where most nodes are likely to exit the network (dynamic availability). It effectively runs two protocols (Casper FFG and LMD Ghost) that together maintain a dynamically available chain with a finalizing prefix. But while maintaining the real-time viability of the network, Gasper sacrifices fast final certainty of transactions (the ability to confirm transactions as quickly as the network allows).
In general, ESQs include:
HotShot -- ESQ is built on the HotShot Consensus protocol, which prioritizes fast final certainty (optimistic responsiveness) over dynamic availability, unlike Gasper. It can also, like Ethereum, expand the number of validators it supports to mind-boggling levels.
Espresso DA - ESQ also provides optional DA options for chains. The mechanism is also used to broaden their consensus.
Sequencer Intelligent Contract This smart contract acts as a light client to verify HotShot consensus and record checkpoints (commitments to points in the sorted transaction log). In addition, it is responsible for managing ESQ's HotShot PoS Consensus pledge.
Network layer - Enables transaction and consensus message communication between nodes participating in HotShot and Espresso DA.
Rollup REST API - L2 rollup API for integrating with Espresso sequencers.
Let's take a closer look at DA. In an optimistic scenario, the high-bandwidth nodes will feed data to all other nodes, and the availability of each individual block is also supported by a small, randomly selected committee. Given the risk of DDoS and bribery attacks on small committees, verifiable Dispersion of Information (VID). Will be used to provide a reliable (but slow) backup path to guarantee DA, as long as a sufficiently high percentage of all nodes (by pledge) are not attacked.
The system was built for capacity expansion, so ESQ wanted to provide cheaper DA for L2 that chose it as a shared sequencer. They will still account for their proofs and status updates to L1 Ethereum, but note that this will make chains that use ESQ "validium" or "optimistic chain" by default, rather than full "rollup" (i.e. their DA is not guaranteed by Ethereum L1). It is better than the data availability committees (dac) The simple implementation of rollup is more powerful, but it is weaker than the security guarantees provided by true rollup.
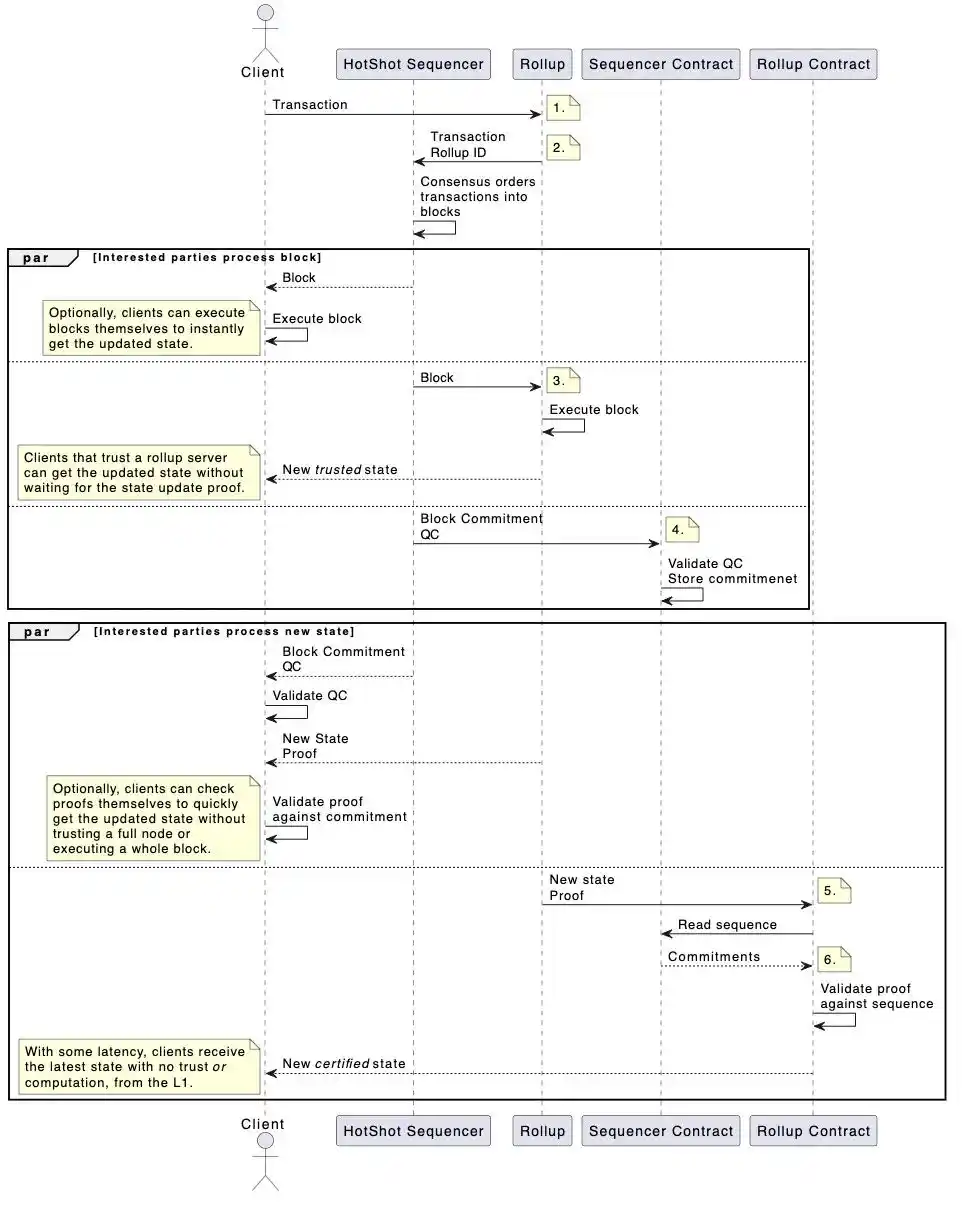
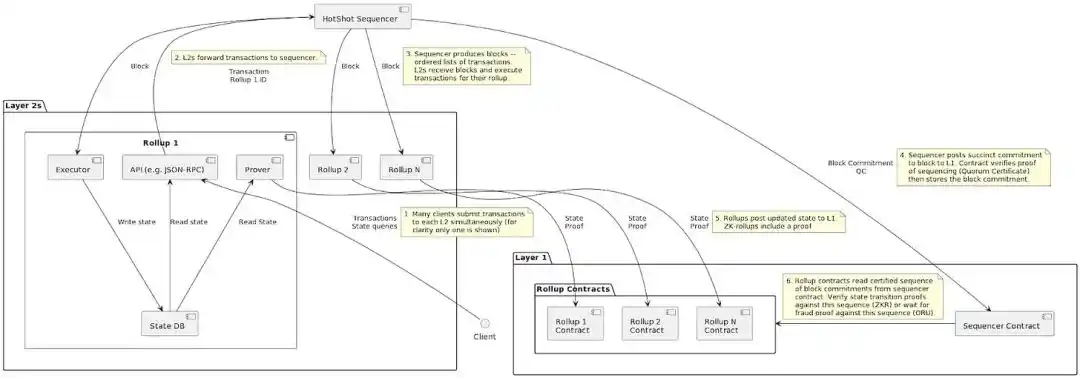
Transaction flow
Sequencer contract - HotShot directly interacts with its L1 sequencer contract. This contract validates the HotShot consensus and provides an interface for other participants to view the blocks it has sorted. The contract stores a block commitment log that can only be appended, rather than a full block. However, anyone can verify any block as promised.
The L2 contract-- Each L2 using ESQ still has its own Ethereum L1 rollup contract. In order to verify the status updates sent to each rollup (with proof of validity/fraud), each rollup contract must have access to the authenticated sequence of blocks that have been sorted to bring a definite status update. The Rollup contract connects with the sequencer contract to query these.
Transactions forwarded to the shared sequencer are sorted and sent back to the rollup effector and prover before being finalised on L1. The shared sequencer also sends a commitment to the block to its L1 sequencer contract, along with a certificate to validate the block. This allows the L1 rollup contract to compare the rollup status update proof to the block commitment certified as consensus output.
A complete view of the transaction flow:
Cross-chain atomicity
As mentioned in the Espresso article, a shared sequencer can provide some exciting use cases related to cross-chain atomicity:
"Shared sorting layers across multiple rollups promise to make cross-chain messaging and bridging cheaper, faster, and more secure. Not having to build a light client for another chain's sequencer is a free benefit with no cost, which creates potential savings upfront. Bridging across rollup can also achieve ongoing savings by removing the need for a given rollup to independently synchronize other rollup consensus. Shared sequentiers also provide security advantages for bridging: It can guarantee that if and only if (even simultaneously) a transaction is finalized in another rollup, that transaction will be finalized in the rollup in which it is located.
In addition, the shared sequencer enhances the user's ability to express atomic dependencies between different rollup transactions. Typically, Alice signs and publishes her rollup-A trade t outside of Bob's rollup-B trade t ". In this case, Alice's transaction may be ordered long before Bob's transaction, giving Bob a long abort option (for example, abort the transaction). This optionality imbalance can be mitigated by sharing sequencers, where Alice and Bob can submit two transactions together as a signed bundle (i.e., the sequencer must treat the two transactions as one)."
As on-chain activity finally begins to grow (I hope), this will be a significant cross-domain impact. It makes a difference. The classic example is "atomic arbitrage". The same asset is trading at two different prices on two different chains. Searchers hope to arbitrage this by executing both trades at the same time without execution risk. For example:
Transaction 1 (T1) - Buy ETH at a low price on Rollup 1 (R1)
Transaction 2 (T2) - Sell ETH at a high price on Rollup 2 (R2)
To achieve atomic arbitrage = either both trades are filled, or neither trade is filled. If both rollups choose the same shared sequencer, it can implement this atomic arbitrage for the searcher. Here sharing sequencers ensures that:
T1 is included in the instruction stream to R1 if and only if:
T2 is also included in the instruction flow to R2
Assuming that the rollup virtual machines execute all transactions in their respective streams in sequence (i.e. no invalid instructions, just some instructions that may throw errors but do not affect state), then we can also guarantee that:
T1 executes on R1 if and only if:
T2 is also executed on R2
However, this is still not the same guarantee as making a transaction on a shared state machine (for example, entirely on Ethereum L1). As mentioned earlier, the shared sequencer does not hold the state of these rollups, and they do not execute transactions. Therefore, there is no complete guarantee that a transaction (on R1 or R2) will not be rolled back upon execution.
Building higher-level primitives directly on top of this is problematic. For example, if an attempt is made to build an instant-destruct-cast cross-chain bridging function on top of this shared sequencer, which simultaneously performs the following operations at the exact same block height:
Burn one of R1's inputs
Cast an output on R2
You may encounter a situation like this:
The destruction action on R1 may throw up an unexpected error, such as being invalidated by another transaction, but
The casting action on R2 will not be invalid for any reason, so it will be fully implemented.
You can see how big a problem this is going to be.
There may be cases where the expected outcome of both transactions can be determined as long as both transactions are included in the input stream and thus executed, but this is often not the case. It is an open question that this process can:
Guarantee - T1 and T2 will be included in their respective flows, and (possibly) both will be executed.
No guarantee is given. - Successful execution of both transactions and the resulting expected state.
This "guarantee" may be sufficient for atomic arbitrage (the searcher already owns the assets needed to execute these transactions on each chain), but it is clearly not synchronous composability for shared state machines. For something like cross-chain flash loans, that guarantee is not enough on its own.
However, this may still be useful in other Settings when used in conjunction with other cross-chain messaging protocols. Let's look at how to facilitate cross-chain atomic NFT exchange when used with the cross-rollup messaging protocol:
- T1 Moves ETH from U1 (user 1) to SC1 (smart contract 1) on R1
-T2 moves NFT from U2 (user 2) to SC2 (smart contract 2) on R2
- If and only if SC1 first receives a message from SC2 confirming that the NFT has been deposited, it will allow U2 to redeem ETH
- SC2 will allow U1 to redeem the NFT if and only if it first receives a message from SC1 confirming that the ETH has been deposited
- Both smart contracts implement a time lock so that if either party fails, all parties can recover their assets
The shared sequencer here allows two users to make an atomic commit in step 1. Some form of cross-rollup messaging mechanism is then used to verify each other's resulting states and unlock assets to perform the exchange.
If there is no shared sequencer to make it atomic, the two sides can agree on a price. But U1 can submit their deal, U2 can wait and decide if they want to abort the deal. With a shared sequencer, their transactions are locked.
So much for the cross-chain atomicity of shared sequencer implementations. To sum up:
The exact strength and usefulness of the assurances provided here remain unproven
This could be useful for cross-chain atom arbitrage, as well as for other applications such as cross-chain swap and NFT trading (perhaps in combination with other messaging protocols)
Provide additional crypto economy assurance. It may be helpful (for example, to deposit collateral) to guarantee certain types of cross-chain transactions
However, you never have an unconditional guarantee on the outcome of your trade (which you can get by executing the trade atomically on a shared state machine)
For other interesting topics on cross-chain atomicity, I recommend checking out:
The hyperchain of Optimism They are also exploring how to use generic sequencers across OP chains. A shared sequencer can reach a consensus and then attempt to implement inter-chain trading of atoms.
Anoma - & have spent Heterogeneous Paxos And Typhon It's a very different approach.
As mentioned earlier, Kalman's cross-rollup force-package transactions.
Summary of shared sequencer
To summarize, the basic idea behind a shared sequencer is:
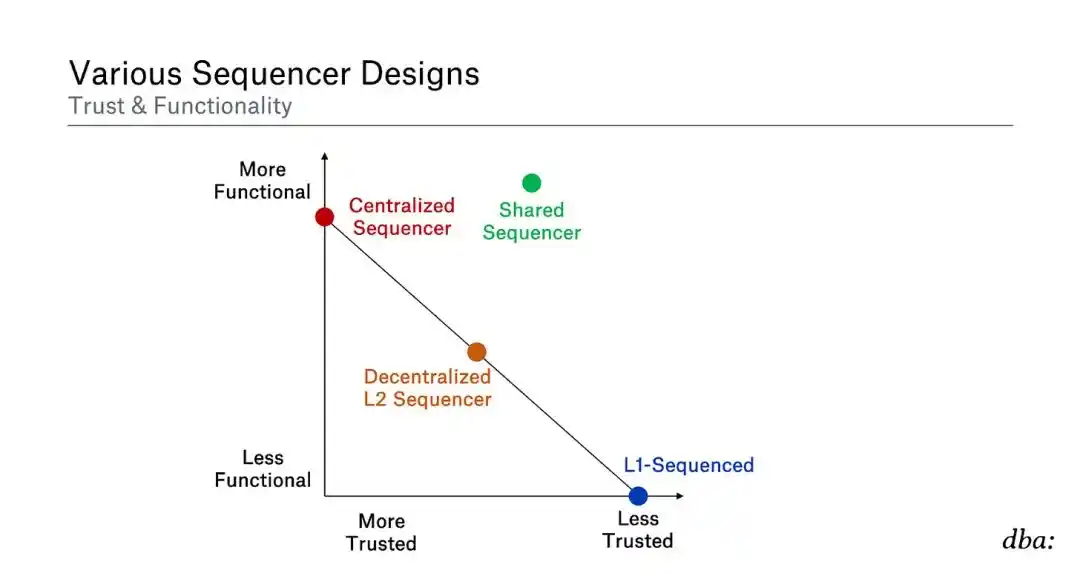
Obviously, this graph is not a law, everything is highly subjective, it is very dependent on the exact structure. But in general the comparison can be made like this:
Centralized Sequencer If you have complete control over the system, it's usually easiest to implement whatever function you want. However, there are sub-optimal guarantees in terms of pre-confirmation strength, forced exit may not be desirable, activity may also be sub-optimal, and so on.
Decentralized L2 sequencer Distributed collections that pledge meaningful value should increase rollup's robustness compared to unitary sequencers. However, depending on how it is implemented, there may be costs such as delays (for example, many L2 nodes may need to vote before confirming the rollup block).
L1 is responsible for sorting. -- Maximize decentralization, resistance to censorship, activity, etc. However, it lacks some features (for example, fast prevalidation, data throughput limitations).
Shared Sequencer -- The function of decentralized sequencer can be obtained from it; Sharing sequencer with others can benefit (gain some degree of atomicity); You don't need to start your own subset of sequencers, etc. However, the transition period before L1 is finalized does have a weaker guarantee than L1 sorting. In addition, a shared sorting layer can aggregate committees, economic security, and so on from multiple rollups into one place (probably much better than if each rollup had its own committee).
Eventually, once the block is finalized at L1, all rollups return to 100% L1 security. Most sequencer designs attempt to give the user very good functionality in the interim period until full security of L1 clearing is achieved, but the guarantee of state is weak. They all have different trade-offs.
SUAVE (Single Unifying Auction for Value Expression)
Decentralized builders vs. shared sequencers
When we talk about these shared layers that attempt to process transactions for many other chains, the differences here can become very confusing. In particular SUAVE This component often appears alongside other terms as "sequencing layer", for example "Decentralised block builder for rollup". To be clear -- SUAVE is very different from the shared sequencer design described above.
Let's see how SUAVE works with Ethereum. SUAVE will not be written into the Ethereum Agreement in any way. Users simply send their transactions to an encrypted trading pool. A network of SUAVE actuators can then generate a block (or part of a block) for Ethereum (or any other chain like it). These blocks will compete with those of traditional Ethereum centralised builders. Ethereum block proposers can listen to both types of blocks and choose which block they want to propose.
Similarly, SUAVE will not replace rollup's mechanism for selecting its blocks. For example, rollup could implement a PoS consensus subset that might operate in much the same way as Ethereum L1. These sequencers/verifiers can then choose which blocks are generated for them by SUAVE.
This is very different from the shared sequencer described above. ** rollup can completely remove the need for decentralized sequencers in shared sequencer designs. They simply outsource this sorting function by adding options such as Metro or ESQ, and can choose to inherit the forking selection rules of these shared sorting layers. ** Ethereum, Arbitrum, Optimism, etc will not change their fork selection rules to select SUAVE for all transaction ordering.
SUAVE doesn't care what the fork selection rules are for your chain, or how your blocks are selected. It is designed to provide the most profitable sorting for any domain. Note that unlike the shared sequencer nodes described earlier, SUAVE executants are usually "fully stateful" (although they may also satisfy certain preferences that do not require state). They need to simulate the results of different transactions to create the optimal ordering.
To see the difference, here is an example of a user who wants to arbitrage atoms across chains. They submit the transaction to SUAVE vs. to a shared sequencer with the following guarantees:
SUAVE + shared sequencer
So now let's talk about how SUAVE interacts with decentralized rollup sequencers, or even shared sequencers? Espresso seems to believe that SUAVE is compatible with ESQ, as they describe in the article. Esqs are designed to be compatible with private trade pool services, such as SUAVE, that can act as block builders. It looks similar to PBS, which we use on Ethereum:
Share proposer = Shared sequencer
Shared builder = SUAVE
As with PBS, the builder can obtain a blind commitment from the proposer (the sequencer here) to propose a given block. The proposer only knows the total utility gained from the proposed block (the builder's bid), not the trading content of the block.
Now putting them all together, let's go back to the example of the searcher who wanted to do cross-chain arbitrage. SUAVE itself can be built and sent to two different rollups:
Block 1 (B1) containing transaction 1 (T1) -- Buy ETH at a low price in Rollup 1 (R1)
Block 2 (B2) containing transaction 2 (T2) -- ETH is sold at a high price in Rollup 2 (R2)
But it is quite possible that B1 will win the auction and B2 will lose (or vice versa). Then, let's think about what happens if the two rollups are selected into the same shared sequencer.
Sharing sequencer nodes is basically stupid.
They don't understand exactly what the transaction is doing, so they need someone (such as SUAVE, or another MEV builder) to build a full block for them if they are to be efficient. Then, the SUAVE actuator can submit B1 and B2 to the shared sequencer, provided that both blocks can be filled or killed (i.e., executed or abandoned atomically).
Now you can get great financial assurance throughout the process:
SUAVE = share builder = can guarantee that both B1 and B2 are included and executed atomically.
Shared sequencer = shared proposer = It is guaranteed that B1 and B2 are included and executed atomically.
Rollup (Restaked Rollups) Rollup (restaked rollups)
I recently published a post on the Flashbots forum about SUAVE's potential economic security model. I argued why rollup might be a better option for SUAVE in the long run than repledge.
Hasu also has some very thoughtful responses to the tradeoff between repledge and rollup, which I encourage you to read. Here is a summary of his response:
Rollup is provided with security/censorship/activity guarantees by L1, but SUAVE does not benefit from this as most chains do because SUAVE chains are not designed for the average user. In fact, Flashbots is looking at how to actively limit the need to bridge assets to SUAVE as a user. Ideally, a chain mainly requires the searcher/builder to keep sufficient operating capital there. This may be much lower than the amount of assets locked up by a traditional rollup for users. In addition, forcing a state transition through L1 may be less valuable to the searcher/builder in that chain than a chain for the average user.
Data availability (DA) is expensive, at least today. We will see how IP-4844 plays into this, and the subsequent demand for DA is likely to grow. On the contrary, I would like to caution that repledge may be more "expensive" for token holders (i.e., if fee income is low and additional tokens need to be issued to ETH repledge to incentivize the formation of adequate economic security models). One is more expensive for the user, while the other is more expensive for the token holder. Which one to choose depends largely on the timing of any potential chains and the maturity of Ethereum's DA layer at the time.
SUAVE needs to report state transitions from other domains back to the main chain (thus unlocking conditional payments to the actuator). Regarding the ability to read state from Ethereum L1 and other Rollups, rollup has a nice trust minimization property.
But I have a new idea - how about doing both? Repledge rollup.

This doesn't solve all the problems Hasu mentioned, but it's still a very interesting new option, especially in the long run.
Rather than just having security guarantees provided by EigenLayer's repledgeers (more like its own borrowed security at L1), rollup can use these EigenLayer repledgeers to maintain its local consensus, but the chain then goes back to Ethereum (i.e., It releases its data and proofs to Ethereum).
As mentioned earlier, rollup could decide to implement its own local consensus in order to achieve a stronger guarantee of short term pre-confirmation and resistance to restructuring before the actual L1 is finalised. So why don't we turn this rollup consensus subset into a set of Ethereum repledgers? Now we have both:
The final certainty before L1 -- a high-value, decentralized repledge consensus -- provides strong near-term resistance to restructuring.
Final certainty after L1 - still a rollup! It publishes its data to Ethereum and can publish ZK/ fraud certificates.
Once L1 is finalized, this is the same security as any rollup. This is just a variation of rollup that implements its own consensus. Only, instead of having its own subset of verifiers on its rollup protected by its own native token, as described earlier, it opted to have Ethereum's repledgeer run Consensus.
Likewise, it would be interesting to see if Celestia is able to implement some form of repledge in its agreement (the current plan is that Celestia's L1 is very small and does not feature smart contracts). I've written before that a rollup written into the agreement would be an interesting direction for Celestia, and native repledge would be another fascinating tool that would allow the free market to decide what features they want to put in. The repledge also helps Celestia's economic security, since the value-accumulation model of the alternative DA layer is still unproven.
Other MEV considerations
The easiest way here (what rollup usually does now) is to run a single sequencer with neat FCFS (first come, first serve) rules. Sequencers simply submit transactions in the order in which they were received. You can reasonably trust a single sequencer to obey FCFS sorting rules, but it will still encourage latency races and related negative externalities in other problems (don't implement POWs to try to solve it). Therefore, even centralized sequencers need to deal with MEVs more effectively.
Some of the solutions mentioned above have implicitly addressed this issue (for example, holding a completely free public auction), but apparently none of the rollups want their users to be sandwiched. So, maybe we need some creative ideas. Combining the benefits of auctions with programmable privacy makes it more interesting.
This is why centralized sequencers now also like to use private transaction pools -- trying to ensure that users don't jump the trade and so on. But decentralization is not easy. If it were open to many sequencers, would you trust them to run their own private transaction pools? Even if you believe that if each sequencer has its own private trading pool and you need to start rotating active sequencer leaders, there might be a problem.
Crypto trading pools are a fascinating area of research to address these issues. I would like to briefly recommend to you the relevant information of this post I just posted:
https://twitter.com/jon_charb/status/1635837710605639683?s=20
In this post, I "ll just give a brief overview of some variations of FCFS proposals.
In this article, I'll briefly outline some variations of the FCFS proposal.
Time Boost
Realizing the limitations and negative externalities of simple FCFS, Arbitrum began exploring new variants of it. More recently, they have proposed a Time Boost mechanism. Basic principle:
The centralized sequencer that needs to be trusted continues to operate a private transaction pool for the user's transactions
The sequencer marks each transaction with a timestamp as it receives it
By default, a trade is executed within 500 milliseconds of receiving it
Users can choose to pay an additional priority package fee for their transaction, giving it a "time boost" that can shave up to 500 milliseconds off the transaction
The formula for calculating Time boost is as follows:
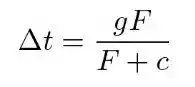
Among them:
F = priority package fee for the transaction
g = Maximum time acceleration available (500 ms)
c is equal to the constant to be determined
Currently, searchers can only express their preference for fast packaging to an Arbitrum sequencer (open many connections, get physically close to it, invest capital in infrastructure, etc.) by minimizing latency to the Arbitrum sequencer. The Time Boost, in turn, reduces the incentive to invest in the aforementioned latency advantage, since searchers can now express their preference for fast packaging by bidding on priority packaging fees.
This is a clear improvement over simple FCFS, but still has some drawbacks in my opinion:
This reduces the incentive for delayed competition, but it does not eliminate it. Minimizing latency always allows the searcher to underbid the competition, and the arc of the chart above shows that the latency advantage is particularly meaningful for high-value MEV opportunities.
It is not clear how effectively transaction pool privacy and timestamps are decentralized.
Searchers' bids lack much else. Searchers can only bid for faster packages, but they cannot express more complex preferences, which would be the case with more flexible explicit auctions (such as the current Ethereum L1).
On a related note, if implemented at this level, there will be no ability to recover failed bids.
FBA-FCFS
Last year Xin from Flashbots proposed an alternative for Arbitrum (FBA-FCFS). This implements a frequent batch auction style variation on Themis. In this scenario:
The nodes report partial ordering to the leader, who then aggregates these into an unordered batch. All transactions are assumed to occur at the same time within a set "fair granularity" of batch times (for example, 500 milliseconds).
The leader then resolves the weak ordering problem within batches through some form of auction.
Similar to the Time Boost proposal, there are attempts to guarantee relatively fast packaging times (less than 500 milliseconds is recommended, but can be changed) and to prevent a jump start through trusted nodes. Similarly, it reduces the incentive for delayed competition by allowing searchers to express their preferences (the preferential packaging fee mechanism) (although it does not completely eliminate all advantages).
For the "fast searcher", the delay advantage that other "slow searchers" cannot compete with at the end of a given batch remains:
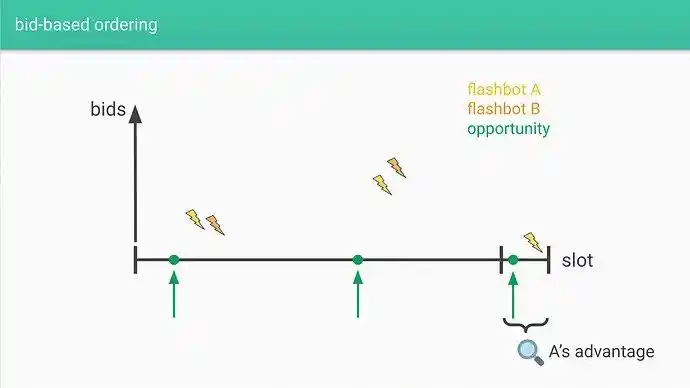
Source: Latency Arms Race Concerns in Blockspace Markets
This is a well-known aspect of these auctions. A longer batch processing time further reduces the percentage of time associated with this latency advantage, despite the higher potential value of the batch. Longer block times can have other effects on MEVs (e.g., fluctuating prices).
To summarize this delay advantage:
Time Boost - A lower latency is always advantageous (lower latency = can always have a lower average bid).
FBA-FCFS - Lower latency is sometimes advantageous (when a small gap between "slow" and "fast" searchers shows relevant information).
About time delay:
Time Boost - The speed at which all user transactions are received with a default delay of 500 milliseconds.
FBA-FCFS -- Batch processing time is 500 ms, so user transactions received during the window can be included in it, averaging away from the midpoint. 500 ms
FBA-FCFS brings more variability (for example, transactions may slide to the next batch based on receipt time), but regular user transactions that do not pay priority packaging fees should have lower average packaging times. In the Time Boost model, time is continuous (there is no concept of blocks), while in the FBA-FCFS model, time is discrete. In summary:

Delay and decentralization
This article is already long and I'm tired, so please read Phil's article for this part. Thanks for :(
conclusion
Hopefully, the reader now has a clearer picture of the path to sequencer decentralization and the associated obstacles. This is one of many challenges rollup will need to address as it matures over the next few years.
Some other interesting areas to explore include:
Interactions at different layers - As sequencers are decentralized, how do they interact with different parts of the trading supply chain? What type of auction (for example, SUAVE) should insert a decentralized subset of sequencers (for example, shared sequencers)?
Transaction cost Mechanism -- Multidimensional resource pricing vs. state determination
L2 fee market - charging "L2 native" fees (e.g. L2 plugging fees) and "L1 native" fees (e.g. L1 data availability fees)
ZK prover Market - How to properly incentivize decentralized and permissionless ZK prover market. This is an important subset of L2 expenses and will have relevance in other contexts.
Rollup's business model - how Rollup tokens and the teams that build them accumulate value and achieve sustainability.
Upgradability and governance - Decentralize these components and reduce trust assumptions while maintaining system flexibility.
Fraud /ZK proof -- Build more robust mechanisms, such as using multiple prover mechanisms.
Original link
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia







