Forum
Forum OPRR
OPRR Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Data
Data

Vitalik on the possible future of Ethereum (Part 4): The Verge

 Summarized by AI
Summarized by AI
Original title: Possible futures of the Ethereum protocol, part 4: The Verge
Original author: Vitalik Buterin
Original translation: Mensh, ChainCatcher
Previous reading: 《Vitalik on the possible future of Ethereum (I): The Merge》, 《Vitalik on the possible future of Ethereum (II): The Surge》, 《Vitalik on the possible future of Ethereum (III): The Scourge》
Special thanks to Justin Drake, Hsia-wei Wanp, Guillaume Ballet, Icinacio, Rosh Rudolf, Lev Soukhanoy Ryan Sean Adams, and Uma Roy for their feedback and review.
One of the most powerful features of blockchains is that anyone can run a node on their computer and verify the correctness of the blockchain. Even if all 9596 nodes running chain consensus (PoW, PoS) immediately agreed to change the rules and started producing blocks according to the new rules, everyone running a fully validating node would refuse to accept the chain. Coin miners who are not part of such a conspiracy will automatically converge on a chain that continues to follow the old rules and continue to build on that chain, and fully validating users will follow that chain.
This is a key difference between blockchains and centralized systems. However, for this feature to be true, running a fully validating node needs to be actually feasible for enough people. This applies to both makers (because if makers don't validate the chain, they are not contributing to enforcing the protocol rules) and ordinary users. Today, it’s possible to run a node on a consumer laptop (including the one I’m using to write this), but it’s difficult to do. The Verge is here to change that, making it computationally cheap to fully validate the chain so that every mobile wallet, browser wallet, and even smartwatch will do it by default.
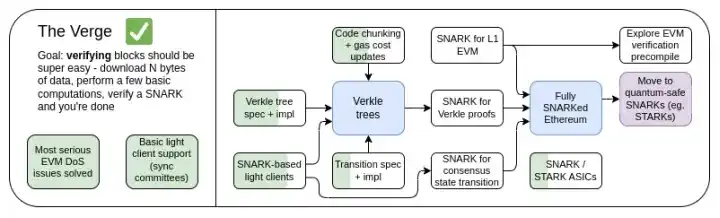
The Verge 2023 Roadmap
Originally, "Verge" referred to the move of Ethereum state storage to Verkle trees - a tree structure that allows for more compact proofs, enabling stateless verification of Ethereum blocks. A node can verify an Ethereum block without storing any Ethereum state (account balances, contract code, storage space, ...) on its hard drive, at the cost of a few hundred KB of proof data and a few hundred milliseconds of extra time to verify a proof. Today, Verge represents a larger vision focused on achieving maximum resource-efficient verification of the Ethereum chain, which includes not only stateless verification techniques, but also the use of SNARKs to verify all Ethereum executions.
Besides the long-standing focus on SNARKs verifying the entire chain, another new question is related to whether Verkle trees are the best technique. Verkle trees are vulnerable to quantum computers, so if we put a Verkle tree in the current KECCAK Merkle Patricia tree, we will have to replace the tree again later. A self-replacement approach for Merkle trees is to just skip the STARKs that use Merkle branches and put them in a binary tree. Historically, this approach has been considered unfeasible due to overhead and technical complexity. Recently though, we’ve seen Starkware prove 1.7 million Poseidon hashes per second on a laptop using ckcle STARKs, and proof times for more “traditional” hashes are decreasing rapidly thanks to technologies like GKB. As a result, The Verge has become more open to several possibilities over the past year.
The Verge: Key Goals
· Stateless clients: Fully validating clients and marking nodes should require no more than a few GB of storage.
· (Long term) Fully validating the chain (consensus and execution) on a smartwatch. Download some data, verify the SNARK, done.
In this chapter
· Stateless Clients: Verkle or STARKs
· Proof of Validity of EVM Execution
· Proof of Validity of Consensus
Stateless Validation: Verkle or STARKs
What Problem Are We Solving?
Today, Ethereum clients need to store hundreds of gigabytes of state data to validate blocks, and this amount is increasing every year. The raw state data grows by about 30GB per year, and a single client must store some additional data on top of it to be able to efficiently update triples.
This reduces the number of users who can run a fully validating Ethereum node: while large hard drives large enough to store all of Ethereum’s state, even years of history, are readily available, the computers people buy by default tend to have only a few hundred gigabytes of storage. The state size also introduces a huge amount of friction to the process of setting up a node for the first time: nodes need to download the entire state, which can take hours or days. This has all sorts of knock-on effects. For example, it makes it significantly more difficult for node makers to upgrade their node setups. Technically, the upgrade can be done without downtime - start a new client, wait for it to sync, then shut down the old client and transfer the keys - but in practice, this is technically very complicated.
How does it work?
Stateless verification is a technique that allows nodes to verify blocks without knowing the entire state. Instead, each block is accompanied by a witness that includes: (i) the values, code, balances, storage at specific locations in the state that the block will access; (ii) cryptographic proofs that these values are correct.
In practice, implementing stateless verification requires changing Ethereum's state tree structure. This is because the current Merkle Patricia tree is extremely unfriendly to implementing any cryptographic proof scheme, especially in the worst case. This is true for both the "original" Merblk fork and the possibility of "wrapping" it into a STARK. The main difficulties stem from some weaknesses of MPT:
1. This is a six-way tree (i.e. each node has 16 children). This means that, in a tree of size N, a proof requires an average of 32*(16-1)*log16(N) = 120* log2(N) bytes, or about 3840 bytes in a tree of 2^32 items. For a binary tree, only 32*(2-1)*log2(N) = 32* log2(N) bytes, or about 1024 bytes.
2. The code is not Merkle-ized. This means that to prove any access to the account code, the entire code needs to be provided, which is at most 24000 bytes.
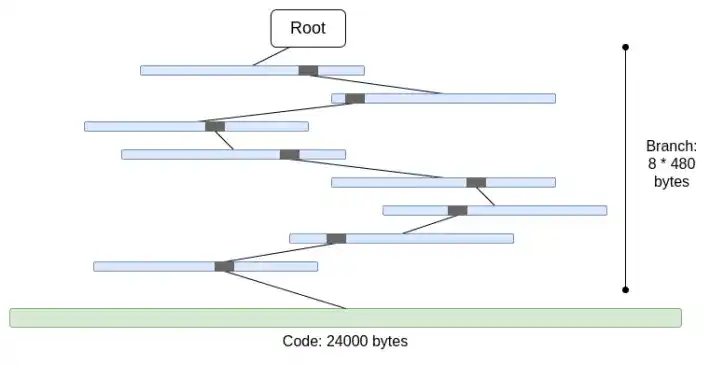
We can calculate the worst case as follows:
30000000 gas / 2400 (cold account reading cost) * (5 * 488 + 24000) = 330000000 bytes
The branch cost is slightly reduced (5*480 instead of 8*480) because when there are more branches, their top parts will be repeated. But even so, the amount of data to be downloaded in one time slot is completely unrealistic. If we try to wrap this with STARKs, we run into two problems: (i) KECCAK is relatively STARK-unfriendly, and (ii) 330MB of data means we have to prove 5 million calls to the KECCAK round function, which is probably impossible to prove on all but the most powerful consumer hardware, even if we can make STARK prove KECCAK more efficient.
If we replace the hex tree with a binary tree directly, and do additional Merkle-ification of the code, the worst case becomes roughly 30000000/2400*32*(32-14+8) = 10400000 bytes (14 is the subtraction of the redundant bits of the 2^14 branches, and 8 is the length of the proof to enter the leaf in the code block). Note that this requires changing the gas cost to charge for accessing each individual code block; EIP-4762 does this. 10.4 MB is much better, but still too much data for many nodes to download in a single time slot. So we need to introduce more powerful techniques. There are two leading solutions in this regard: Verkle trees and STARKed binary hash trees.
Verkle Trees
Verkle trees use vector commitments based on elliptic curves to make shorter proofs. The key to unlocking this is that the part of the proof corresponding to each parent-child relationship is only 32 bytes, regardless of the width of the tree. The only limit on the width of the proof tree is that if the proof tree is too wide, the proof becomes less computationally efficient. The implementation proposed for Ethereum has a width of 256.
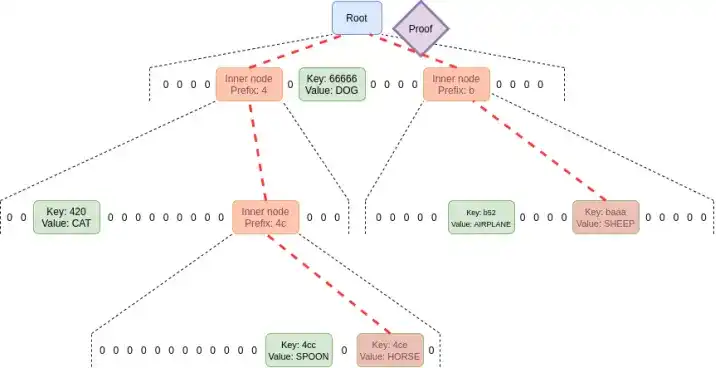
Thus, the size of a single branch in the proof becomes 32 - 1og256(N) = 4* log2(N) bytes. Therefore, the theoretical maximum proof size is roughly 30000000 / 2400 *32* (32 -14 + 8) / 8 = 130000 bytes (the actual calculation result is slightly different due to the uneven distribution of state blocks, but it is OK as a first approximation).
Also note that in all of the above examples, this "worst case" is not the worst case: a worse case would be for an attacker to deliberately "mine" two addresses to have a long common prefix in the tree, and read data from one of them, which could extend the worst-case branch length by another factor of 2. But even with that, the worst-case proof length for a Verkle tree is 2.6MB, which is roughly consistent with the current worst-case checksum data.
We also use this caveat to do another thing: we make it very cheap to access "adjacent" storage space: either many code blocks of the same contract, or adjacent storage slots. EIP-4762 provides a definition of adjacency, with a gas fee of only 200 for adjacency access. In the case of adjacent access, the worst-case proof size becomes 30000000 / 200*32 - 4800800 bytes, which is still roughly within the tolerance. If we want to reduce this for security reasons, we can increase the fee for adjacent accesses slightly.
STARKed Binary Hash Trees
The principle of this technique is self-explanatory: you just make a binary tree of proofs up to 10.4 MB, proving the value in the block, and then replace the proof with the STARK of the proof. This way, the proof itself only contains the data being proved, plus a fixed overhead of 100-300kB from the actual STARK.
The main challenge here is verification time. We can do basically the same calculation as above, except that instead of counting bytes, we count hashes. A 10.4 MB block means 330,000 hashes. If you add the possibility of an attacker "mining" addresses with a long common prefix in the tree, the worst case hash count comes to about 660,000 hashes. So if we can prove 200,000 hashes per second, we’ll be fine.
These numbers have been achieved on consumer laptops using the Poseidon hash function, which was specifically designed to be STARK-friendly. However, the Poseidon system is still relatively immature, so many people don’t trust its security yet. Therefore, there are two realistic paths forward:
1. Quickly do a lot of security analysis on Poseidon and become familiar enough with it to deploy at L1
2. Use a more “conservative” hash function like SHA256 or BLAKE
If proving a conservative hash function, Starkware’s STARK circle can only prove 10-30k hashes per second on a consumer laptop at the time of writing. STARK technology is improving rapidly, though. Even today, GKR-based technology is shown to increase this speed to the 100-2O0k range.
Witness Use Cases Beyond Validating Blocks
Beyond validating blocks, there are three other key use cases that require more efficient stateless validation:
· Mempool: When a transaction is broadcast, nodes in the P2P network need to verify that the transaction is valid before rebroadcasting it. Today validation includes verifying the signature, but also checking for sufficient balances and correct prefixes. In the future (e.g. using native account abstractions like EIP-7701), this will likely involve running some EVM code that does some state access. If nodes are stateless, transactions will need to be accompanied by proofs proving the state object.
· Inclusion lists: This is a proposed feature that would allow (potentially small and unsophisticated) proof-of-stake validators to force the next block to include a transaction, regardless of the wishes of (potentially large and complex) block builders. This would reduce the ability of powerful parties to manipulate the blockchain by delaying transactions. This would require validators to have a way to verify the validity of transactions in the inclusion list, though.
· Light clients: If we want users to access the chain through wallets (like Metamask, Rainbow, Rabby, etc.), to do this they need to run a light client (like Helios). The Helios core module provides users with a verified state root. And for a fully trustless experience, users need to verify the state root for every RPC they make. Calls provide proofs (e.g., for Ethereum call requests (users need to prove all states accessed during the call).
What all of these use cases have in common is that they require quite a few proofs, but each is small. Therefore, STARK proofs are not practical for them; instead, the most realistic approach is to use Merkle branches directly. Another advantage of Merkle branches is that they are updatable: given a proof of state object X rooted at block B, if a child block B2 and its witness are received, the proof can be updated to be rooted at block B2. Verkle proofs are also natively updatable.
How it relates to existing research:
· Verkle trees
· John Kuszmaul’s original paper on Verkle trees
· Starkware
· Poseidon2 paper
· Ajtai (alternative fast hash function based on lattice hardness)
· Verkle.info
What else can be done?
The main work remaining is
1. More analysis on the consequences of EIP-4762 (stateless gas cost changes)
2. More work on completing and testing the transition procedure, which is a major part of the complexity of any stateless environment implementation
3. More security analysis of Poseidon, Ajtai, and other "STARK-friendly" hash functions
4. Further development of ultra-efficient STARK protocol features for "conservative" (or "traditional") hashing, e.g. based on Binius or GKR's views.
In addition, we will soon decide on one of the three options: (i) Verkle trees, (ii) STARK-friendly hash functions, and (iii) conservative hash functions. Their properties can be roughly summarized in the table below:
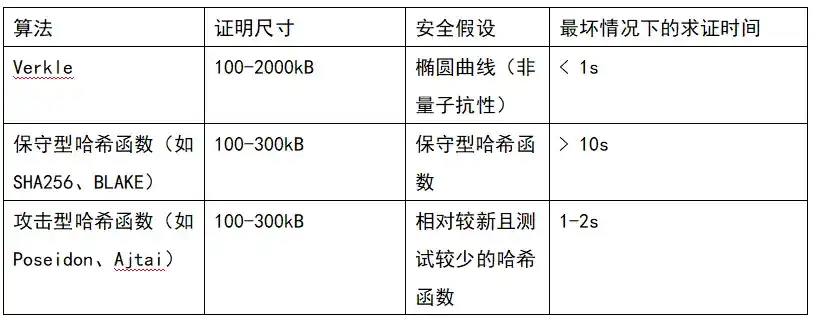
Beyond these “headline numbers”, there are other important considerations:
· The Verkle tree code is fairly mature these days. Using anything other than Verkle would delay deployment, most likely delaying a hard fork. This is OK, especially if we need extra time for hash function analysis or validator implementation, or if we have other important features we want to include in Ethereum sooner.
· Updating the state root using hashes is faster than using Verkle trees. This means that hash-based approaches can reduce full node sync times.
· Verkle trees have an interesting witness update property — Verkle tree witnesses are updateable. This property is useful for mempools, containment lists, and other use cases, and may also help make the implementation more efficient: if the state object is updated, the witness of the second-to-last layer can be updated without reading the contents of the last layer.
· Verkle trees are harder to SNARK. If we want to get proof size down to a few kilobytes, Verkle proofs introduce some difficulties. This is because the verification of Verkle proofs introduces a lot of 256-bit operations, which requires the proof system to either have a lot of overhead or have a custom internal structure itself that contains the 256-bit Verkle proof part. This is not a problem for statelessness itself, but it introduces more difficulties.
If we want to get Verkle witness updatability in a quantum-safe and reasonably efficient way, another possible path is lattice-based Merkle trees.
If the worst-case proof system is not efficient enough, we can also make up for it with the unexpected tool of multidimensional gas: separate gas limits for (i) calldata; (ii) computation; (iii) state access, and possibly other different resources. Multidimensional gas increases complexity, but in exchange it more strictly limits the ratio between average and worst-case. With multidimensional gas, the maximum number of branches that need to be proved in theory might be reduced from 12500 to, for example, 3000. This would make BLAKE3 (barely) usable even today.
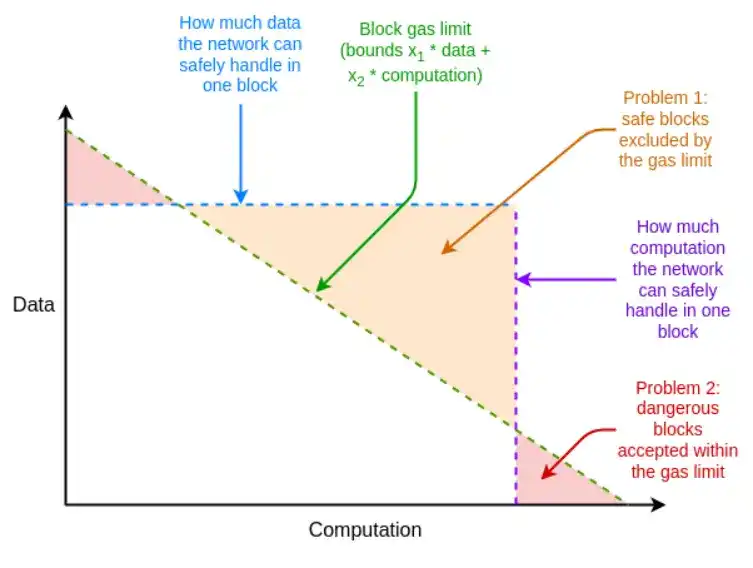
Multiple gas dimensions allow the resource limits of blocks to be closer to the resource limits of the underlying hardware
Another unexpected tool is to delay the state root computation until the time slot after the block. This gives us a full 12 seconds to compute the state root, which means that even in the most extreme case, only 60,000 hashes per second of proof time is sufficient, which again makes us think that BLAKE3 is only barely adequate.
The downside of this approach is that it adds a light client latency of one time slot, but there are more clever techniques to reduce this latency to just the proof generation latency. For example, proofs can be broadcast on the network as soon as any node generates them, rather than waiting for the next block.
How does it interact with the rest of the roadmap?
Solving the statelessness problem greatly increases the difficulty of single-player pinpointing. This would become more feasible if there were techniques to lower the minimum balance for single-player spotting, like Orbit SSF, or application-layer policies like squad spotting.
Multidimensional gas analysis would become much easier if EOF was also introduced. This is because the main execution complexity of multidimensional gas comes from handling child calls that do not pass the full gas of the parent call, and EOF would make this problem trivial by simply making such child calls illegal (and native account abstraction would provide an in-protocol alternative for some of the current major uses of gas).
There is also an important synergy between stateless validation and history expiration. Today, clients must store nearly 1TB of history data; this is several times the state data. Even if the client is stateless, the dream of a nearly storage-free client will not be realized unless we can relieve the client of the responsibility of storing history data. The first step in this regard is EIP-4444, which also means storing history data in torrents or portals.
Proof of Validity of EVM Execution
What Problem Are We Solving?
The long-term goal of Ethereum block validation is clear - it should be possible to validate an Ethereum block by (i) downloading the block, or even just a small sampling of the data availability in the block, and (ii) verifying a small proof that the block is valid. This would be an extremely low-resource operation that could be done in a mobile client, browser wallet, or even in another chain (without the data availability part).
To get to this point, SNARK or STARK proofs are needed for (i) the consensus layer (i.e. proof of stake) and (ii) the execution layer (i.e. EVM). The former is a challenge in itself and should be addressed in the process of further continuous improvements to the consensus layer (e.g. for single-slot finality). The latter requires proof of EVM execution.
What is it and how does it work?
Formally, in the Ethereum specification, the EVM is defined as a state transition function: you have some pre-state S, a block B, and you are computing a post-state S' = STF(S, B). If the user is using a light client, they do not have S and S', or even E in full; instead, they have a pre-state root R, a post-state root R', and a block hash H.
· Public input: previous state root R, post-state root R', block hash H
· Private input: program block body B, objects in the state accessed by program block Q, the same objects after executing program block Q', state proof (such as Merkle branch) P
· Claim 1: P is a valid proof that Q contains some part of the state represented by R
· Claim 2: If STF is run on Q, (i) the execution process only accesses objects inside Q, (ii) the data block is valid, and (iii) the result is Q'
· Claim 3: If the new state root is recomputed using information from Q' and P, R' will be obtained
If this situation exists, we can have a light client that fully verifies Ethereum EVM execution. This makes the client resources already quite low. To achieve a true fully validating Ethereum client, the same work needs to be done on the consensus side.
Implementations of validity proofs for EVM computations already exist and are heavily used by L2. There is still a lot of work to be done to make EVM validity proofs feasible in L1.
How does it connect to existing research?
· EFPSE ZK-EVM (now discontinued due to better options)
· Zeth, which works by compiling the EVM into the RISC-0 ZK-VM
· The ZK-EVM Formal Verification Project
What else can be done?
Today, validity proofs for electronic ledger systems fall short in two areas: security and verification time.
A secure validity proof needs to guarantee that the SNARK actually verifies the EVM's computation and that there are no vulnerabilities. The two main techniques for improving security are multi-validators and formal verification. Multi-validators refers to having multiple independently written validity proof implementations, just like having multiple clients, and clients accept a block if it is proven by a large enough subset of these implementations. Formal verification involves using tools commonly used to prove mathematical theorems, such as Lean4, to prove that a proof of validity accepts only correct executions of the underlying EVM specification (e.g. EVM K semantics or the Ethereum Execution Layer Specification (EELS) written in python).
Fast enough verification time means that any Ethereum block can be verified in less than 4 seconds. Today, we are still far from this goal, although we are much closer than we thought two years ago. To achieve this goal, we need progress in three directions:
Parallelization - The fastest EVM verifier currently proves an Ethereum block in 15 seconds on average. It achieves this by parallelizing across hundreds of GPUs and then aggregating their work at the end. In theory, we know exactly how to make an EVM verifier that can prove a computation in O(log(N)) time: have a GPU do each step, and then make a "convergence tree":
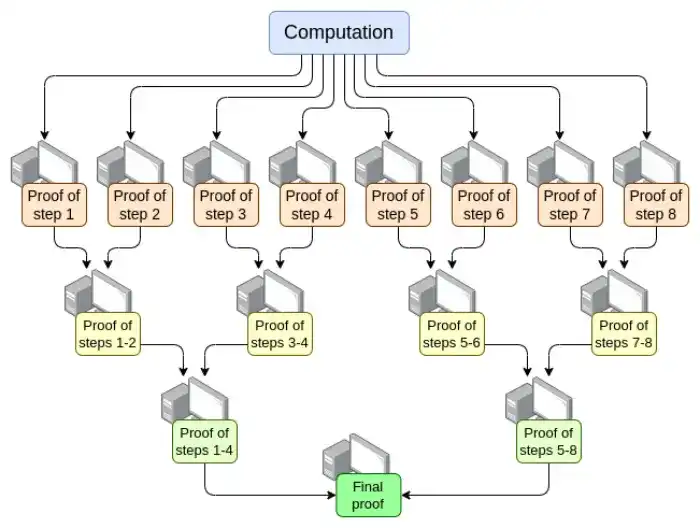
There are challenges to implementing this. Even in the worst case, where a very large transaction takes up an entire block, the computation cannot be split up by transaction, but must be split up by opcode (of the underlying virtual machine like the EVM or RISC-V). Ensuring that the "memory" of the virtual machine is consistent between different parts of the proof is a key implementation challenge. If we can achieve this recursive proof, though, then we know that the prover latency problem has been solved, even if nothing else has improved.
· Proof system optimizations - New proof systems like Orion, Binius, GRK, and more are likely to lead to another major reduction in verification time for general purpose computation.
· Other changes to EVM gas costs - Many things in the EVM can be optimized to make them more favorable to provers, especially in the worst case. If an attacker can construct a block that blocks provers for ten minutes, then being able to prove a normal Ethereum block in 4 seconds is not enough. The required EVM changes can be roughly divided into the following categories:
- Changes in gas costs - If an operation takes a long time to prove, it should have a high gas cost even if it is relatively fast to compute. EIP-7667 is an EIP proposed to deal with the worst problems in this regard: it greatly increases the gas cost of (traditional) hash functions, because the opcodes and precompiles for these functions are relatively cheap. To compensate for these gas cost increases, we can reduce the gas cost of EVM opcodes that are relatively cheap to prove, thereby keeping the average throughput unchanged.
- Data Structure Replacement — In addition to replacing the state trie with something more STARK-friendly, we also need to replace the transaction list, receipt trie, and other structures that are expensive to prove. Etan Kissling’s EIP to move transaction and receipt structures to SSZ is a step in this direction.
In addition to this, the two tools mentioned in the previous section (multidimensional gas and delayed state roots) can also help in this regard. However, it is worth noting that unlike stateless verification, using these two tools means that we already have enough technology to do what we need at the moment, and even with these technologies, full ZK-EVM verification requires more work — just less work.
One thing not mentioned above is prover hardware: using GPUs, FPGAs, and ASICs to generate proofs faster. Fabric Cryptography, Cysic, and Accseal are three companies making progress in this area. This is very valuable for L2, but is unlikely to be a decisive consideration for L1, as there is a strong desire for L1 to remain highly decentralized, which means proof generation must be within reasonable reach of Ethereum users and should not be bottlenecked by a single company's hardware. L2 can make more aggressive tradeoffs.
There is more work to be done in these areas:
· Parallelizing proofs requires that different parts of the proof system can "share memory" (like lookup tables). We know the techniques to do this, but they need to be implemented.
· We need to do more analysis to figure out the ideal set of gas cost variations that minimize worst-case verification time.
· We need to do more work on the proof system
Possible costs are:
· Security vs. verifier time: It is possible to reduce verifier time if more aggressive hash functions, more complex proof systems, or more aggressive security assumptions or other design choices are made.
· Decentralization vs. prover time: The community needs to agree on the "specs" of the prover hardware to target. Is it okay to require the prover to be a large-scale entity? Do we want a high-end consumer laptop to prove an Ethereum block in 4 seconds? Something in between?
· The degree of breaking backwards compatibility: Other deficiencies could be compensated by more aggressive gas cost changes, but this is more likely to disproportionately increase the cost of some applications, forcing developers to rewrite and redeploy code to remain economically viable. Again, both tools have their own complexities and drawbacks.
How does it interact with the rest of the roadmap?
The core technology needed to implement L1 EVM validity proofs is largely shared with two other areas:
· L2 validity proofs (i.e. “ZK rollup”)
· The stateless “STARK binary hash proof” approach
Successfully implementing validity proofs on L1 will eventually enable easy single-person staking: even the weakest computers (including phones or smartwatches) will be able to stake. This further increases the value of solving other limitations of single-person staking (such as the 32ETH minimum).
In addition, L1 EVM validity proofs can greatly increase the gas limit of L1.
Consensus validity proofs
What problem are we solving?
If we want to fully verify an Ethereum block with SNARKs, then the execution of the EVM isn’t the only part we need to prove. We also need to prove consensus, the part of the system that handles deposits, withdrawals, signatures, validator balance updates, and other elements of the Proof of Stake portion of Ethereum.
Consensus is much simpler than the EVM, but the challenge with it is that we don’t have an L2 EVM convolution, so most of that work has to be done anyway. As a result, any implementation that proves Ethereum consensus will need to “start from scratch,” even though the proving system itself is a shared effort that can be built on top of it.
What is it and how does it work?
The Beacon Chain is defined as a state transition function, just like the EVM. The state transition function consists of three main parts:
· ECADD (used to verify BLS signatures)
· Pairing (used to verify BLS signatures)
· SHA256 hash (used to read and update state)
In each block, we need to prove 1-16 BLS12-381 ECADDs per validator (it may be more than one, as signatures may be included in multiple sets). This can be compensated by subset precomputation techniques, so we can say that each validator only needs to prove one BLS12-381 ECADD. Currently, there are 30,000 validator signatures per slot. In the future, as single-slot finality is achieved, this situation could change in two directions: If we take the "brute force" route, the number of validators per slot could increase to 1 million. At the same time, if Orbit SSF is adopted, the number of validators will remain at 32,768, or even decrease to 8,192.
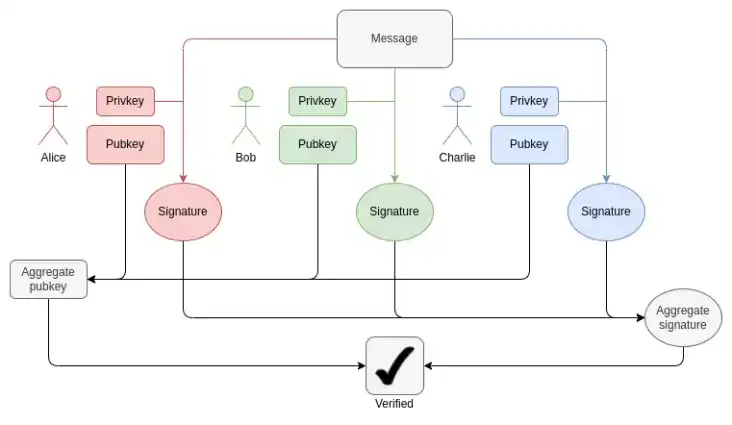
How BLS aggregation works: Verifying the total signature only requires one ECADD per participant, not one ECMUL. But 30,000 ECADDs is still a lot of proofs.
In terms of pairings, there are currently a maximum of 128 proofs per slot, which means 128 pairings need to be verified. With ElP-7549 and further modifications, this can be reduced to 16 per slot. The number of pairings is small, but the cost is extremely high: each pairing takes thousands of times longer to run (or prove) than an ECADD.
A major challenge in proving BLS12-381 operations is that there are no convenient curves with a curve order equal to the BLS12-381 field size, which adds considerable overhead to any proving system. On the other hand, the Verkle trees proposed for Ethereum are built using Bandersnatch curves, making BLS12-381 a native curve for proving Verkle branches in SNARK systems. A naive implementation can prove 100 G1 additions per second; making proofs fast enough will almost certainly require clever techniques like GKR.
The worst case for SHA256 hashes right now is the epoch transition block, where the entire validator short balanced tree and a large number of validator balances are updated. Each validator short balanced tree is only one byte, so 1 MB of data is rehashed. This is equivalent to 32768 SHA256 calls. If a thousand validators have balances above or below a threshold, the effective balances in the validator records need to be updated, which equates to a thousand Merkle branches, so perhaps ten thousand hashes. The shuffle mechanism requires 90 bits per validator (hence 11 MB of data), but this can be computed at any time in an epoch. In the case of single-slot finality, these numbers may increase or decrease on a case-by-case basis. Shuffling becomes unnecessary, although Orbit may restore the need to some extent.
Another challenge is the need to re-fetch all validator states, including public keys, to validate a block. For 1 million validators, just reading the public keys would require 48 million bytes, plus the Merkle branches. This would require millions of hashes per epoch. If we had to prove the validity of PoS, a realistic approach would be some form of incremental verifiable computation: store a separate data structure within the proof system that is optimized for efficient lookups, and prove updates to that structure.
In summary, the challenges are numerous. Meeting them most effectively would likely require a deep redesign of the beacon chain, which could potentially be done in parallel with the move to single-slot finality. Features of such a redesign could include:
· Changes in hash functions: The "full" SHA256 hash function is now used, so each call corresponds to two underlying compression function calls due to padding. We could gain at least 2x by using the SHA256 compression function instead. If we use Poseidon instead, we might get a 100x gain, thus completely solving all of our problems (at least in terms of hashrate): at 1.7 million hashes per second (54MB), even a million verification records can be "read" into a proof in seconds.
· In the case of Orbit, store the shuffled validator records directly: if a certain number of validators (such as 8192 or 32768) are chosen to be the committee for a given slot, put them directly into the state next to each other, so that the public keys of all validators can be read into the proof with minimal hashing. This also makes all balance updates efficient.
· Signature aggregation: Any high-performance signature aggregation scheme will involve some kind of recursive proof, where different nodes in the network do intermediate proofs for subsets of signatures. This naturally distributes the proof work to multiple nodes in the network, greatly reducing the workload of the "final prover".
· Other signature schemes: For Lamport+ Merkle signatures, we need 256 + 32 hashes to verify the signature; multiplied by 32768 signers, we get 9437184 hashes. Optimizations to the signature scheme can further improve this result by a small constant factor. If we use Poseidon, this can be proved in a single slot. But in practice, it is faster to use a recursive aggregation scheme.
How does it connect to existing research?
· Concise Ethereum consensus proof (synchronous committee only)
· Helios inside a concise SP1
· Concise BLS12-381 precompile
· BLS set signature verification based on Halo2
What’s left to do, and what are the trade-offs:
In reality, it will take us years to get proofs of validity for Ethereum consensus. This is roughly the same amount of time it took us to achieve single-slot finality, Orbit, modify the signature algorithm, and the security analysis required to have enough confidence to use a “radical” hash function like Poseidon. Therefore, the most sensible approach is to solve these other problems and consider STARK friendliness while solving them.
The main trade-off is likely to be in the order of operations, between a more gradual approach to reforming Ethereum’s consensus layer and a more radical “change many at once” approach. For the EVM, the gradual approach makes sense because it minimizes disruption to backwards compatibility. There is less of a backwards compatibility impact for the consensus layer, and there are benefits to a more “holistic” rethink of various details of how the beacon chain is built to best optimize SNARK-friendliness.
How does it interact with the rest of the roadmap?
STARK-friendliness must be a top consideration in any long-term redesign of Ethereum PoS, especially single-slot finality, Orbit, signature scheme changes, and signature aggregation.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia